
Introduction to fuzzing: How to automatically discover bugs
Table of Contents

Fuzzing techniques are used to detect security breaches and other bugs by generating inputs not contemplated by the programmer
¿What’s Fuzzing? – Security testing
Fuzzing is a technique used by programmers, security researchers and bug hunters to test and discover vulnerabilities in software.
This technique consists of performing automated tests on an application, introducing random data and modifications of expected data inputs , in order to provoke faults in its behaviour.
Fuzzing history
Software development has evolved at great speeds since its beginnings. Subject to relatively low development cost when compared to other sectors such as in hardware design, it has demonstrated the ability to iterate multiple generations for each hardware generation. To this capacity for change, one must add the expectations of software users as motivation for change and evolution. This allows us to grasp that the needs of software developers have had to evolve as much as their products.
Software history leaves traces of the needs that have shaped programming languages, tools and even paradigms that have made it possible to achieve previously inconceivable goals.
An example of this could be the creation of the “C” programming language, sometimes considered the first high-level language. This language is conceived as closer to human language than its predecessors and allows programmers to abstract their code from the machine that will ultimately execute it.
Another possible milestone was the conception of object-oriented programming. It is a paradigm shift where the concept of «object» is introduced. An object can contain both data and code, opposed to traditional variables that only contain data. A priori, this slight conceptual difference does not seem to have enough implications to completely revolutionize an industry. However, this change allowed the modularization of much of the software into entities, enabling the decoupling of the development of these parts. Object-oriented programming is not restricted to this, but this small idea gave rise to much more complex concepts where it was possible to define relationships between these objects such as inheritance or polymorphism.
Regardless of these paradigm shifts that have come to shape programming languages themselves, throughout software history there have been changes important enough to drive the creation of tools that adapt to almost all programming languages. The concept of «test» has been so relevant to this guild that «testing» tools have been developed for almost any programming language. The idea consists, fundamentally, in programming tests that verify that the code responds in the expected manner to a set of known inputs that are representative of the use cases for which the software has been designed.
This concept has even given rise to a paradigm in which the software specifications are first designed, then the tests are programmed and finally this software is programmed based on the specifications so that it meets and passes the tests. This paradigm is named Test Driven Development or TDD.
Testing helps maintaining a level of functionality to the software that is constantly changing, but they are limited to providing expected data to the software, which must react appropriately. So, what happens when we malform that input data or use unexpected data as inputs to the software?
Fuzzing is a technique that seeks to reveal bugs in the software by generating inputs not considered by the programmer. Sometimes these unexpected inputs are capable of triggering bugs that cause a program to crash instead of displaying an error message or properly shutting down.
These crashes can be a response to memory misuse, sometimes having very high security implications. These input data could cause a service interruption (DoS – Denial of Service). On other occasions, poor memory management allows us to exfiltrate data that we should not have access to (Data exfiltration). In the worst of all situations, the ability to write to specific memory regions would allow us to inject pieces of code and execute them (RCE – Remote Code Execution).
It should also be noted that since the number of possible program inputs not considered by a programmer is enormous, this seems like a good way to study a piece of software to look for bugs in an automated way.
The difficult side of fuzzing
The fundamentals of this technique are simple and can be summed up in one question: “What happens when unexpected data is introduced in a software data entry?”. However, this is a complex technique that requires time and resources to obtain good results.
When we compare fuzzing with testing multiple differences appear that highlight the complexity of what is trying to be achieved.
One of these most relevant differences is exemplified when a programmer decides to write tests for his software. The programmer must consider how far his tests should go. He subsequently implements them and from this moment onwards, the execution of these tests has a determined and limited duration in time. Ignoring that software evolves, that users discover new bugs and that other maintenance tasks may require the writing of new tests, this task, after its design phase, is simple enough so that its execution can be automated.
Fuzzing, however, involves introducing unexpected data, which covers an infinite search spectrum. You can always look for a new variation of the input data and you do not always have information beforehand about whether that new variation is going to produce a failure or not.
Another advantage of analysis using fuzzing techniques is that you can check the security of an application and how resilient it is to fault injection attacks without having access to its code, since the tests can be performed against the final compiled executable with the intention of testing it in a real environment.
This difference is a significant barrier. Fuzzing requires an investment of time and computing resources without promising results. In contrast, the test, whose execution is short, reports with high certainty possible operation problems.
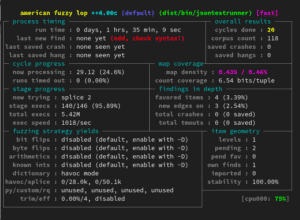
It is also relevant to notice that the results that this technique can provide depend fundamentally on how the malformed input data is generated. This is a difficult task and there are many alternatives that must be studied and understood to obtain relevant results.
An example of this would be the study of the security of a network protocol that implements some kind of integrity check. If it were decided to apply one of the most general techniques in fuzzing in this study case, such as capturing valid data frames of the protocol and modifying some of their fields randomly to send them back to a server, the probability of obtaining results would be very low. Since this protocol implements a data consistency check, modifying arbitrary positions without updating the check field will not allow us to pass the first check, thus performing a study only on the first barrier of the protocol and ignoring deeper layers that may have implementation flaws.
Finally, it is worth mentioning that when this technique manages to produce an application failure, or hundreds of them depending on how skilled we have been with the generation of inputs, and once we have managed to reproduce one of these failures, it is when we proceed to classify the information obtained during this fuzzing process and study the origin of the problem. Depending on the volume of bugs that we have found, a triage will have to be done to address those that may seem more serious first and then analyze them in detail to determine their origin or how to improve our code so that these vulnerabilities are solved.
Fuzzing relevance and adoption
Due to the difficulties implementing fuzzing tests, developer adoption is low. It requires time, knowledge and does not promise results. On the other hand, impact of vulnerable software can be very high, which is why some choose to use this technique.
Traditionally, a reactive approach has been chosen in terms of security. Users are expected to report bugs and other problems, or third parties find security flaws and publish them. Some vendors include incentives to report these bugs through bounty programs.
For these reasons, traditionally there has only been a real incentive for third parties to apply this technique. There are many free tools to fuzz software such as AFL/AFL++, FuzzDB or Ffuf among others, but very few of them have been used by software developers. However they are common among security researchers since these tools really have the ability to find bugs in an automated way.
There are some projects that try to close this gap. OSS-Fuzz, for example, is focused on providing and automating part of the fuzzing setup process so that open-source projects receive reports of possible security flaws. The OSS Fuzz project has discovered more than 36,000 bugs as of January 2022.
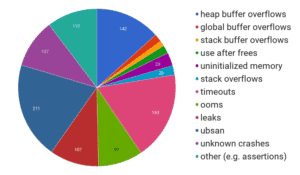
https://opensource.googleblog.com/2017/05/oss-fuzz-five-months-later-and.html
Open-source software fuzzing projects – Let’s fuzz
For those curious about fuzzing techniques, a list with some open-source fuzzers actively maintained is shown below.
- AFL (American Fuzzy Lop) / AFL++. Probably the most known fuzzing project. AFL has not been updated since 2017 and that is why AFL++, a more updated and recent fork, emerges. It is a very extensive project with quite some complexity. It allows applying various fuzzing strategies and has support for binaries of multiple architectures via QEMU or Unicorn emulator.
- LibFuzzer. This project is designed for those cases where there is access to the source code. In order to integrate LibFuzzer, an objective function must be implemented. This function will be compiled together with the code to be tested using Clang. LibFuzzer uses parts of the LLVM backend to track execution and tries to cover most of the execution lines of the binary. It is one of the most focused to be integrated during the development process of the application or library.
- Honggfuzz. Another project with some complexity and many options to configure. This project is maintained by Google and is part of the OSS Fuzz initiative. It stands out for its ability to run on very different operating systems such as Linux, *BSD, Android, Windows, Darwing/OS X…
There are hundreds of projects like Fuzzilli, boofuzz, jazzer, etc. Given so many options, the question arises as to which one to choose and which one is the best. There is no clear answer for this, since as we mentioned before, each example case has special requirements. It should also be noted that each project implements its own automatic bug search strategies, so combining different projects can lead to results that individual use could not achieve.
Conclusions
Fuzzing is a complex technique that requires a dedication of time, effort and very high resources investment.
Despite its drawbacks, the importance of achieving secure applications and software means that there are initiatives for their use and resources that allow the discovery of security gaps and other bugs in an automated way, that an auditor doing a code review would probably not find.