
OWASP FSTM, Etapa 9: Explotación de ejecutables
Tabla de contenidos

La explotación de ejecutables es el paso final dentro de un análisis de firmware, en el que se desarrolla un exploit para una vulnerabilidad descubierta en fases anteriores
Las técnicas de explotación de vulnerabilidades varían mucho dependiendo del tipo de vulnerabilidad y del componente al que afecten, aunque, habitualmente, las más graves y dañinas provienen de ejecutables sin las medidas de seguridad pertinentes o que hacen uso de funciones vulnerables.
Si las fases de análisis anteriores han dado frutos, en este punto se habrá descubierto una vulnerabilidad o indicios de ella en alguno de los componentes del firmware de un dispositivo OT o IoT. En ocasiones, esa vulnerabilidad se encuentra en un ejecutable, para el cual se puede escribir una prueba de concepto (PoC) o exploit.
Las PoC y los exploits pueden variar dependiendo del tipo de vulnerabilidad. Sin embargo, si esta se encuentra en la programación de un ejecutable, una vulnerabilidad de buffer overflow puede conllevar ejecución de código remoto, para lo cual existen un conjunto de herramientas y técnicas conocidas.
En este artículo se presentan técnicas y herramientas para la explotación de estos ejecutables en el marco de una auditoría de seguridad IoT exhaustiva siguiendo la metodología OWASP FSTM.
1 Técnicas de explotación de ejecutables
Habitualmente, las vulnerabilidades más graves y difíciles de detectar en un firmware provienen de bugs en los ejecutables que contiene. Son difíciles de detectar, puesto que suelen requerir inspeccionar en detalle el código fuente o el ejecutable compilado y, a priori, no dan señales de su existencia. Sin embargo, algunas pueden exponer vulnerabilidades graves y su explotación exitosa es definitiva en un análisis de firmware.
1.1 Buffer overflow
Las formas más comunes de vulnerabilidades en ejecutables son debidas a la corrupción de memoria. En esta categoría entran los desbordamientos de buffer, que pueden conllevar una vulnerabilidad de ejecución remota de código.
Un buffer es una región de memoria en la que se almacena un valor temporalmente. En C, estos buffers se implementan como arrays con una capacidad fija. Si el código no comprueba la longitud de un valor en la entrada, se escriben datos más allá de los límites del buffer: se desborda el buffer.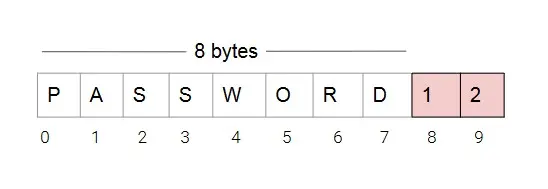 Debido a la organización de las variables automáticas en memoria, que son creadas en el stack, respecto a la dirección de retorno de la función que la contiene, los datos desbordados pueden alcanzar la dirección de retorno y sobrescribirla.
Debido a la organización de las variables automáticas en memoria, que son creadas en el stack, respecto a la dirección de retorno de la función que la contiene, los datos desbordados pueden alcanzar la dirección de retorno y sobrescribirla.
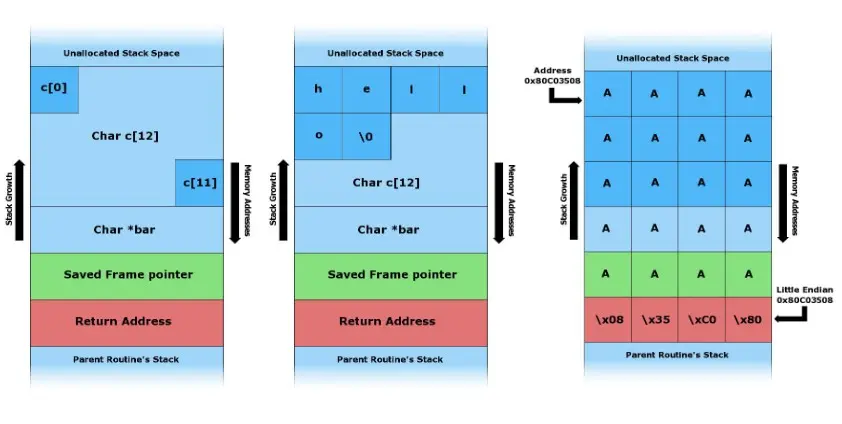
Con esta técnica de explotación de ejecutables, se puede escribir una dirección de retorno arbitraria y controlar el flujo de ejecución.
Además, este mismo bug permite al atacante inyectar una shellcode en la memoria y escribir la dirección de esta shellcode en la dirección de retorno, logrando ejecutar código arbitrario. El uso de NX (no execute) impide la ejecución de shellcodes en el stack.
1.2 Format string attack
Este tipo de bug está producido por un uso incorrecto de la función printf en C. Cuando la cadena de formato de esta función, que es el primer argumento, indica más valores que el número de argumentos siguientes, se puede empezar a leer valores del stack. A priori, este problema no parece explotable, pero cuando el usuario tiene control sobre el string de formato como en el código siguiente permite operaciones no contempladas por el programador:
#include <stdio.h>
int main(void) {
char buffer[30];gets(buffer);
printf(buffer);
return 0;
}
En este caso, un atacante puede introducir una cadena de formato en la entrada y printf la interpreta como tal, de forma que se pueden leer los contenidos del stack:
$ ./test
%x %x %x %x %x %x
f7f74080 0 5657b1c0 782573fc 20782520 25207825
De hecho, se puede continuar leyendo hasta obtener los datos contenidos en el buffer, que el propio atacante ha introducido. Esto abre la posibilidad de interpretar parte de la misma entrada como una dirección de memoria con el modificador de formato %s, permitiendo leer una posición de memoria aleatoria.
Además, el modificador de formato %n escribe en la dirección de memoria proporcionada el número de caracteres escritos en stdout, de forma que, combinándolo con la técnica anterior, se pueden escribir valores enteros en posiciones de memoria arbitrarias.
1.3 Heap overflow
La técnica de heap overflow, otro proceso para la explotación de ejecutables, es muy similar a la técnica de buffer overflow o stack overflow. Pero aquella se lleva a cabo en el espacio de memoria dinámica en lugar de en el stack.
Cuando un programador aloja memoria dinámica, esta se aloja linealmente. Si por motivos de construcción de un programa logramos sobrepasar los límites de esta memoria alojada podríamos sobrescribir valores en memoria colindante.
En este caso el atacante ha de hacer un análisis más detallado de qué cosas se pueden encontrar en la memoria colindante ya que la memoria dinámica no es tan estructurada como el stack. Si en memoria colindante nos encontramos con algún puntero en el que el programador confía podríamos sobrescribir su valor. Esto puede tener muy diversos ejemplos, desde lograr que el programa copie datos en secciones no deseadas hasta incluso la toma de control de la ejecución.
1.4 Use After Free
Esta vulnerabilidad se debe al uso de punteros a memoria dinámica después de haber liberado sus contenidos. Debido al funcionamiento de glibc al asignar memoria dinámica, con las condiciones correctas, un espacio de memoria recién liberado puede reutilizarse y ser asignado en la siguiente llamada a malloc.
Esto genera situaciones en las que dos punteros aparentemente distintos tienen acceso a la misma dirección de memoria y, si el atacante puede alcanzar uno de ellos y modificar sus contenidos, puede afectar inesperadamente al otro.
Por ejemplo, considerando el siguiente código:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>int main(void) {
char* buffer0;
char* buffer1;buffer0 = (char *) malloc(11);
/* tareas */
free(buffer0);buffer1 = (char *) malloc(11);
fgets(buffer1, 11, stdin);if (strncmp(buffer0, “go forward”, 10) == 0) {
printf(“flag\n”);
}
free(buffer1);
return 0;
}
Aparentemente, buffer0 y buffer1 apuntan a regiones de memoria diferentes y no deberían interferirse mutuamente. Sin embargo, el atacante puede escribir en la dirección de buffer1, que, debido a que malloc asigna el espacio de memoria recién liberado, apunta a la misma dirección de memoria que buffer0, por lo que le puede asignar valor.
1.5 Double Free
Esta técnica de explotación de ejecutables se centra en la implementación de las funciones malloc y free. Si de alguna manera se logra forzar que se libere dos veces el mismo bloque de memoria, esto hará que malloc devuelva dos veces el mismo bloque de memoria para dos asignaciones distintas.
Para ejemplificar este comportamiento se adjunta el siguiente trozo de pseudo código:
char * a = malloc(10); // 0x55971353c210
char *b = malloc(10); // 0x55971353c230
char *c = malloc(10); // 0x55971353c250free(a); // Liberamos “a”
free(b); // Liberamos b para evitar el “double free or corruption (fasttop)”
free(a); // Volvemos a liberar “a”char * d = malloc(10); // 0x55971353c210
char * e = malloc(10); // 0x55971353c230
char * f = malloc(10); // 0x55971353c210 – Misma dirección que “d”!
Más allá de la capacidad de escribir en f y d simultáneamente existe un efecto importante y también explotable de esta implementación. En el ejemplo anterior, la misma sección de memoria existe de manera alojada y libre al mismo tiempo durante un periodo de tiempo. Si en este periodo de tiempo se puede escribir en la estructura de la memoria alojada, se ha obtenido el control sobre la dirección de memoria donde se hará el siguiente malloc.
char * a = malloc(0x20); // 0x55971353c210
free(a);
free(a); // Doble liberación!
char * b = malloc(0x20); // 0x55971353c210 – Misma dirección que “a”!
// 0x55971353c210 existe como ocupado en “b”
// y como liberado en “a”
strcpy(b, «\x78\x56\x34\x12»); // Escribimos en “b” una dirección arbitraria
malloc(0x20); // Ignoramos este alojamiento de memoria
char * c = malloc(0x20); // 0x12345678 – Apunta a la dirección arbitraria!
1.6 Otras técnicas de explotación de ejecutables
Además de las mencionadas anteriormente, existen muchas otras técnicas de explotación de ejecutables avanzadas que pueden ser de utilidad. Este artículo no pretende ser una guía exhaustiva de cada una de ellas, pero se listan a continuación algunas de las más conocidas:
- Null Byte Poisoning.
- Forging Chunks.
- Shrinking Free Chunks.
- House of Spirit.
- House of Lore.
- House of Force.
- House of Einherjar.
- Unlink exploit.
2 Protección de binarios y hardening
Cuando se ha encontrado un indicio de vulnerabilidad en un ejecutable, antes de proceder a tratar de explotar esta vulnerabilidad, ha de hacerse un estudio de que qué medidas de prevención hay desplegadas en el entorno en el que se ejecuta.
Existen protecciones contra diversas técnicas de explotación de ejecutables que se encuentran en el ejecutable en sí mismo o en la manera en la que se ha compilado. Por otro lado, el kernel también puede habilitar algunas medidas contra la explotación. Algunas de las técnicas y medidas de protección más importantes se explican a continuación:
2.1 PIE (Position Independent Executables)
Esta opción de compilación permite la generación de código que puede ejecutarse de manera independiente de la dirección absoluta de memoria en la que ha sido cargada. Esto se logra mediante el direccionamiento relativo de memoria y evitando el uso de referencias absolutas.
Esta técnica permite que el binario sea cargado en distintas direcciones de memoria cada vez que se ejecuta, dificultando el uso de técnicas ROP (Return Oriented Programming) que se explicarán más abajo.
Dado que el código debe tener la capacidad de saltar entre direcciones, cuando se usa PIE, es obligatorio usar direcciones relativas. Este mismo sistema puede usarse para elaborar exploits, saltándonos la protección.
2.2 RELRO (Relocation Read-Only)
Aunque existe en dos modalidades (parcial y total), se resume en un incremento de la protección de la sección GOT de un ejecutable. Esta sección del ejecutable es responsable de almacenar las direcciones de funciones externas al programa y presentes en librerías.
El objetivo de esta protección es prevenir la sobre escritura de las direcciones en las que se encuentran las funciones de libc.
La protección parcial puede saltarse cuando en un exploit tenemos la capacidad para escribir en posiciones arbitrarias de memoria (como el caso de un format string attack).
2.3 NX (NoeXecute)
Esta técnica se asegura de que el stack sea una zona que no permita la ejecución de código y que sea dedicada solo a su función original de almacenar datos.
Tanto el binario debe habilitarla como el procesador soportarla para que esta protección se active. Impide a un atacante insertar su propio código en la zona del stack para su posterior ejecución.
Para saltarse esta protección se ha desarrollado la técnica ROP (Return Oriented Programming) donde se usan trozos de código existentes en el programa para lograr el objetivo deseado en lugar de escribir los shellcodes tradicionales.
2.4 Stack Canaries
Son valores que el compilador inserta en llamadas a funciones y que se aseguran de que un stack overflow no ha sobrescrito el valor de retorno de una función. Se trata de valores que sirven como verificación antes de volver al punto de ejecución que ha llamado a una función.
Existen técnicas que permiten saltarnos estas protecciones. Un ejemplo sería descubrir el valor del canary antes de realizar la explotación y colocar el valor en su sitio durante la explotación. Esto se puede hacer en los ataques de formato de cadenas ya que permiten leer posiciones de memoria arbitrarias.
En el caso de las máquinas de 32-bits o menos se puede hacer un ataque de fuerza bruta al canario. A veces es la única técnica que puede obtener resultado para saltar esta protección.
2.5 ASLR (Address Space Layout Randomization)
En este caso, el sistema operativo o el kernel son los encargados de habilitar la aleatorización de las direcciones de distintos espacios de memoria. Cuando nos encontramos con ASLR habilitado, cada vez que se ejecute un proceso, las direcciones del heap, stack, mmap base e incluso la base del ejecutable principal serán distintas. Esto reduce la probabilidad de que un atacante pueda reproducir con certeza un ataque en el que se produzcan corrupciones en la memoria.
También implica que las direcciones de dependencias como libc se encuentren en distintas direcciones cada vez que se ejecuta el programa al igual que con PIE.
2.6 Comprobación automática
Dada la cantidad de protecciones y técnicas para evitar la explotación binaria, resulta poco práctico escribir un exploit para posteriormente descubrir que no va a funcionar porque el stack no permite ejecución o porque algunas de las referencias a las que llama el exploit cambian de dirección con cada ejecución…
Por ello existen múltiples herramientas que nos informan de las protecciones habilitadas para un binario concreto y del entorno en el que se ejecuta.
Algunas de las alternativas son Hardening check o checksec.sh. Su uso es sencillo y se ejemplifica a continuación:
$ checksec –file=/bin/ls
RELRO STACK CANARY NX PIE RPATH RUNPATH Symbols FORTIFY Fortified Fortifiable FILE
Full RELRO Canary found NX enabled PIE enabled No RPATH No RUNPATH No Symbols Yes 6 18 /bin/ls
3 Técnicas de evasión
Existen múltiples técnicas y herramientas para evitar las protecciones de ejecutables que se han presentado. A continuación, se hace una descripción de las más relevantes.
3.1 Return-Oriented Programming
Como ya se ha mencionado, la ejecución de shellcodes desde el stack no es directamente posible si el mecanismo NX está habilitado, que impide la ejecución de código en una zona de datos. Sin embargo, existen técnicas para evadir esta protección.
En concreto, la programación orientada a retornos o ROP consiste en encontrar fragmentos de código terminados en una instrucción ret (retorno), llamados gadgets. Una vez encontrados esos fragmentos, se utiliza una vulnerabilidad de buffer overflow para sobrescribir la dirección de retorno de la función original con la dirección del primer gadget, y las posiciones siguientes con las direcciones de una cadena ordenada de gadgets.
El resultado es que, al volver de la función original, se ejecuta el primer gadget, que, al terminar y sin haber modificado los valores del stack, ejecuta un retorno que salta al segundo gadget. Así se ejecuta toda la cadena de gadgets, que constituyen el shellcode.
La escritura de un shellcode con ROP debe tener en cuenta aquellas instrucciones que modifican el stack, ya que sobrescribirían la cadena. Esto puede evitarse intercalando los valores necesarios para la ejecución cada gadget. También se pueden ejecutar llamadas a función colocando la dirección de la función, seguida de la dirección de retorno correspondiente al siguiente gadget.
Para el paso de parámetros, dependiendo de la convención de llamada a funciones, pueden pasarse en el stack, tras la dirección de retorno, o utilizar, previamente a la llamada, gadgets que escriban los registros adecuados.
La limitación de la ROP es la búsqueda de gadgets para componer la shellcode. Esta técnica suele enfocarse a la búsqueda de funciones de libc, como system, que permite ejecutar un archivo del sistema, aunque el uso de ASLR puede complicar la tarea. Esta técnica es conocida como ret2libc, y existen otras similares que utilizan ROP con diferentes propósitos, como ret2csu o ret2dlresolve.
Incluso, en casos en los que no hay espacio suficiente en el stack para completar una cadena de gadgets, existen diferentes técnicas para tomar el control del puntero del stack para fingir su dirección y obtener más espacio. Estas técnicas son conocidas como stack pivoting.
También existen herramientas como ROPgadget facilitan la búsqueda de gadgets en un ejecutable.

3.2 GOT Overwrite
La sección GOT de un ejecutable contiene una tabla con referencias a funciones externas al propio ejecutable ya cargadas en memoria.
Cuando en un ejecutable nos encontramos con la protección NX habilitada, una de las opciones para saltarnos esta protección es sobrescribir la tabla GOT para llamar a una función de nuestra elección cuando nos encontremos con cualquier otra llamada externa.
Para ilustrar el concepto, a continuación, se adjunta un programa vulnerable:
char buffer[300];
while(1) {
fgets(buffer, sizeof(buffer), stdin);
printf(buffer);
}
En este caso, mediante una vulnerabilidad de string format podríamos sobrescribir la entrada GOT de la función printf para que apunte a system de manera que en la segunda iteración del bucle el código equivalente fuese el siguiente:
char buffer[300];
while(1) {
fgets(buffer, sizeof(buffer), stdin);
system(buffer);
}
3.3 Canary leaking y brute forcing
Si en un ejecutable encontramos una vulnerabilidad de formato de cadena, es posible volcar el stack hasta encontrar el valor del canary para que cuando realicemos un buffer overflow podamos incluir el canary en el exploit, evadiendo esta técnica de protección.
También es teóricamente posible realizar un ataque de fuerza bruta al valor de protección del stack relanzando el proceso hasta lograr una colisión. Esto es un proceso lento y tedioso que no siempre podrá realizarse. Es especialmente inverosímil en plataformas de 64 bits donde el ataque no es práctico en casi ninguna situación.
El ataque de fuerza bruta podría ser especialmente práctico en el escenario en el que podamos interactuar con un fork del proceso original. Los forks de un proceso heredan un mapa de memoria igual al del padre por lo que conservan su canary. Esto nos asegura que podemos intentar valores manteniendo un canary constante y acotando el tiempo de ejecución del ataque.
3.4 Syscalls
Las llamadas a sistema tienen el acrónimo syscall. Este es el mecanismo por el cual un programa realiza la llamada al kernel para que realice tareas específicas como crear procesos, I/O de periféricos y otras que requieren la elevación de permisos. Al navegar por la lista de syscalls el lector se percatará que hay algunas similares a las funciones de libc como open(), fork() o read(). Esto se debe a que estas funciones son wrappers de las llamadas a sistema para facilitar la implementación a los desarrolladores.
La llamada a sistema en Linux está desencadenada por la instrucción int80. Cuando el kernel comprueba el valor almacenado en RAX (el valor del número de syscall) identificando qué syscall debe de ejecutarse. El resto de los parámetros pueden almacenarse en RDI, RSI, RDX, etc. y cada parámetro tiene un significado distinto en función de cada llamada. Existe un caso notable que es execve.
La syscall execve ejecuta el programado suministrado en el parámetro RDI, el parámetro arvp en RSI y el parámetro envp en RDX. Es interesante porque si no existe la función system se puede usar para llamar a /bin/sh en su lugar. La ejecución sería con el parámetro en un puntero a /bin/sh a RDI, introduciendo valor 0 en RSI y TDX (para poder generar una shell es necesario que los parámetros arv y envp sean NULL). En la red se pueden encontrar numerosas pruebas de concepto.
Se pueden obtener gadgets para la ejecución de system y la obtención de un terminal utilizando ROP.
3.5 Sigreturn-Oriented Programming
La técnica SROP consiste en ejecutar un buffer overflow para sobrescribir el stack de una llamada a un manejador de señal (signal handler). El manejador de señal, al ejecutarse, guarda el estado de los registros, además de la dirección de retorno, en el stack, y retorna con las llamadas al sistema sigreturn, que recuperan el estado de los registros y vuelven a la dirección de retorno.
Lograr sobrescribir estos valores permite controlar el valor de cada registro, lo cual ofrece un control total sobre el flujo de ejecución, aunque puede ser complejo de ejecutar sin producir errores.
3.6 Malloc hook overwrite
El lenguaje C tiene una funcionalidad característica llamada __malloc_hook, según la página de GNU se define como «la variable al puntero que ejecuta malloc cada vez que es llamado».
Por otro lado, un one_gadget es simplemente un comando execve(“/bin/sh”) que está presente en la librería glibc. Si se logra sobrescribir el valor de __malloc_hook con la dirección de one_gadget, al llamar a malloc, se obtendrá inmediatamente un terminal. Aunque, en muchos casos, esto puede generar un segmentation fault.
3.7 NOP sleds
Un NOP slide, sled o ramp es una secuencia de instrucciones NOP (no operation) destinadas a llevar a la CPU hasta el final del flujo de ejecución de instrucciones. Generalmente se usa para llevar la ejecución por el camino deseado. Es una técnica muy utilizada en la elaboración de exploits.
Esta técnica es la más antigua y utilizada para explotar stack buffer overflows. Es un método de fuerza bruta para encontrar la región de memoria donde están localizadas las instrucciones que se desean explotar a costa de aumentar el tamaño de la superficie de memoria atacada. El formato de este sería similar al siguiente ejemplo:
from pwn import *
context.binary = ELF(‘./vuln’)
p = process()
payload = b’\x90′ * 240 # The NOPs
payload += asm(shellcraft.sh()) # The shellcode
payload = payload.ljust(312, b’A’) # Padding
payload += p32(0xffffcfb4 + 120) # Address of the buffer + half nop lengthlog.info(p.clean())
p.sendline(payload)
p.interactive()
Evidentemente, no siempre es la mejor forma de proceder a la explotación de ejecutables. En ocasiones, los tamaños de buffer disponibles no permitirán incluir NOP sleds del tamaño deseado. Sin embargo, en algunos sistemas será la única forma de evadir las medidas de hardening de las aplicaciones para conseguir un ataque fructífero.
La explotación de ejecutables es una tarea compleja y propensa a errores, que requiere de experiencia, tiempo y esfuerzo. Sin embargo, lograr la explotación exitosa de un ejecutable puede vulnerar la seguridad de todo el sistema, por lo que es muy útil conocer las diferentes técnicas existentes y practicarlas para aplicarlas en análisis de firmwares.
Además, en el caso de los ejecutables que se utilizan en firmware, es sorprendentemente común encontrar que carecen de las protecciones básicas ante la explotación, por lo que pueden ser especialmente efectivas.
Referencias
- https://github.com/ProhtMeyhet/hardening-check
- https://github.com/slimm609/checksec.sh
- https://ir0nstone.gitbook.io/notes/
- https://github.com/carlospolop/hacktricks
- https://github.com/JonathanSalwan/ROPgadget
- https://heap-exploitation.dhavalkapil.com/
Este artículo forma parte de una serie de articulos sobre OWASP
- Metodología OWASP, el faro que ilumina los cíber riesgos
- OWASP: Top 10 de vulnerabilidades en aplicaciones web
- Análisis de seguridad en IoT y embebidos siguiendo OWASP
- OWASP FSTM, etapa 1: Reconocimiento y búsqueda de información
- OWASP FSTM, etapa 2: Obtención del firmware de dispositivos IoT
- OWASP FSTM, etapa 3: Análisis del firmware
- OWASP FSTM, etapa 4: Extracción del sistema de ficheros
- OWASP FSTM, etapa 5: Análisis del sistema de ficheros
- OWASP FSTM etapa 6: emulación del firmware
- OWASP FSTM, etapa 7: Análisis dinámico
- OWASP FSTM, etapa 8: Análisis en tiempo de ejecución
- OWASP FSTM, Etapa 9: Explotación de ejecutables
- Análisis de seguridad IOT con OWASP FSTM
- OWASP SAMM: Evaluar y mejorar la seguridad del software empresarial
- OWASP: Top 10 de riesgos en aplicaciones móviles