
Introducción al fuzzing: Cómo buscar bugs de manera automatizada
Tabla de contenidos

Las técnicas de fuzzing sirven para detectar brechas de seguridad y otros bugs mediante la generación de entradas no contempladas por el programador
¿Qué es el fuzzing? – Testing de seguridad
El fuzzing es una técnica utilizada tanto por programadores como por investigadores de seguridad y cazadores de bugs para descubrir vulnerabilidades en un programa.
Está técnica consite en la realización de pruebas automatizadas sobre una aplicación, introduciendo datos aleatorios y modificaciones de entradas de datos esperadas por el software, para provocar fallos en su comportamiento.
Historia del Fuzzing
El desarrollo de software es un sector que ha evolucionado a pasos agigantados desde sus inicios. Sujeto a un coste de cambio relativamente bajo con respecto a otros sectores como el del hardware, ha demostrado la capacidad de iterar varias generaciones por cada generación de hardware. A esta capacidad de cambio tenemos que sumar las expectativas de los usuarios de software como motivación para el cambio y la evolución. Esto nos permite intuir que las necesidades de los desarrolladores de software han tenido que evolucionar tanto como sus productos.
La historia del software deja trazas de las necesidades que han conformado lenguajes de programación, herramientas y hasta paradigmas que han permitido alcanzar objetivos antes inconcebibles.
Un ejemplo podría ser la creación del lenguaje «C», en ocasiones considerado como el primer lenguaje de alto nivel. Este lenguaje se concibe como más cercano al lenguaje humano que sus antecesores y permite a los programadores abstraer su código de la máquina que finalmente lo ejecutará.
Otro posible hito fue la concepción de la programación orientada a objetos. Se trata de un cambio de paradigma donde se introduce el concepto de «objeto» que puede contener tanto datos como código, frente a las tradicionales variables que contienen datos. A priori, esta ligera diferencia conceptual no parece tener implicaciones suficientes como para revolucionar una industria por completo. Sin embargo, este cambio permitió la modularización de gran parte del software en entidades, habilitando el desacople del desarrollo de estas partes. La programación orientada a objetos no se restringe a esto, sino esta pequeña idea dio lugar a conceptos mucho más complejos donde se permitió definir relaciones entre estos objetos como la herencia o el polimorfismo.
Independientemente de estos cambios de paradigma que han llegado a marcar los propios lenguajes de programación, a lo largo de esta historia han tenido lugar cambios lo suficientemente importantes como para crear herramientas que se adapten a casi todos los lenguajes de programación. El concepto de «test» ha sido tan relevante para este gremio que se han desarrollado herramientas de «testing» para casi cualquier lenguaje de programación. La idea consiste, fundamentalmente, en programar tests que verifiquen que el código responde de manera esperada ante un set de entradas conocidas y representativas de los casos de uso para los que el software ha sido diseñado.
Este concepto ha dado lugar incluso a un paradigma en el que primero se diseñan las especificaciones del software, posteriormente se programan los tests y por último se programa este software en base a las especificaciones de manera que cumpla y pase los tests (Test Driven Development o TDD).
Los tests ayudan a mantener un nivel de funcionalidad al software que está en constante cambio, pero se limitan a proporcionar datos esperados al software, el cual debe reaccionar de manera adecuada. Entonces, ¿qué pasa cuando malformamos esos datos de entrada o usamos datos inesperados como entradas al software?
El «fuzzing» es una técnica que busca obtener fallos en el software mediante la generación de entradas no contempladas por el programador. A veces estas entradas no contempladas son capaces de generar fallos que hagan que un programa se cierre abruptamente en lugar de mostrar un mensaje de error o cerrarse de una manera adecuada.
Estos cierres abruptos pueden ser la respuesta a un mal uso de la memoria, teniendo a veces implicaciones de seguridad muy elevadas. Esos datos de entrada podrían causar la interrupción de un servicio (DoS – Denial of Service). En otras ocasiones, la mala gestión de la memoria nos permite exfiltrar datos a los que no deberíamos tener acceso (Data exfiltration). En la peor de todas las situaciones, la posibilidad de escribir en regiones concretas de memoria nos permitiría inyectar trozos de código y ejecutarlos (RCE – Remote Code Execution).
También cabe destacar que debido a que la cantidad de entradas no contempladas por un programador es enorme, esta parece una buena vía para estudiar un trozo de software de cara a buscar bugs de manera automatizada.
Dificultades de la técnica de fuzzing
Los fundamentos de esta técnica son sencillos y se pueden resumir en una pregunta: ¿Qué sucede cuando se introducen datos inesperados en una entrada de datos de un software?. Sin embargo, esta es una técnica compleja que requiere tiempo y recursos para obtener buenos resultados.
Cuando comparamos el fuzzing con el testing aparecen múltiples diferencias que destacan la complejidad de lo que se intenta lograr.
Una de las diferencias más relevantes se puede observar cuando un programador decide escribir tests para su software. Este programador ha de plantearse el ejercicio de hasta donde deben llegar sus tests. Posteriormente los implementa y a partir de este momento la ejecución de estos tests tiene una duración determinada y acotada. Obviando que el software evoluciona, que los usuarios descubren nuevas vulnerabilidades y que otras tareas de mantenimiento pueden exigir la escritura de nuevos tests, esta tarea, después de su fase de diseño, es lo suficientemente sencilla como para automatizar su ejecución.
El fuzzing, sin embargo, plantea introducir datos no esperados, que abarcan un espectro de búsqueda infinito. Siempre se puede buscar una variación nueva de los datos de entrada y no siempre se tiene información, a priori, de si esa nueva variación va a producir un fallo o no.
Otra ventaja de los análisis mediante técnicas de fuzzing es que puedes comprobar la seguridad de una aplicación y como de resistente es a los ataques de inyección de fallos sin necesidad de contar o conocer el código de esta, ya que las pruebas se realizan contra el código ejecutable con intención de probarla en un entorno real.
Esta diferencia supone una barrera importante. El fuzzing requiere una inversión de tiempo y recursos de computación sin prometer resultados. En contraposición, el testing, cuya ejecución es corta, informa con certeza de problemas de operación.
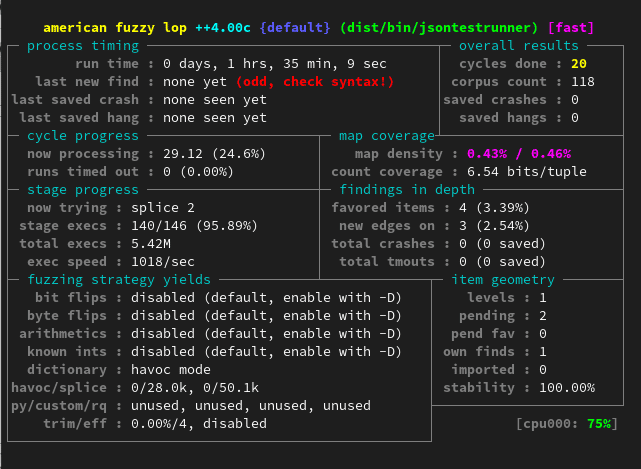
También cabe destacar que los resultados que puede aportar esta técnica dependen fundamentalmente de lo bien que se generen esos datos de entrada malformados. Esto es una tarea difícil y existen muchas alternativas que hay que estudiar y comprender para obtener resultados relevantes.
Un ejemplo de esto sería el estudio de la seguridad de un protocolo de red que implemente algún tipo de comprobación de integridad. Si para este caso se decidiese aplicar una de las técnicas más generalistas en el fuzzing, como podría ser capturar tramas de datos válidas de este protocolo y modificar algunos de sus campos aleatoriamente para volver a enviarlas a un servidor, la probabilidad de obtener resultados sería muy baja. Puesto que este protocolo implementa una comprobación de coherencia de datos, el modificar posiciones arbitrarias sin actualizar el campo de comprobación no nos permitirá pasar esta primera comprobación, realizando un estudio sólo sobre la primera barrera del protocolo e ignorando las capas más profundas que pueden tener fallos de implementación.
Por último, cabe destacar que cuando esta técnica logra producir un fallo de la aplicación, o cientos de ellos en función de lo hábiles que hayamos sido con la generación de entradas, y una vez hemos logrado reproducir uno de estos fallos es cuando se procede a clasificar la información obtenida durante este proceso de fuzzing y estudiar el origen del problema.
En función del volumen de fallos que hemos encontrado habrá que hacer un triage para abordar aquellos que puedan parecer más graves primero. Y, posteriormente, analizarlos en detalle para determinar cuál es el origen o como mejorar nuestro código en el software para que no existan estas vulnerabilidades.
Importancia y adopción del fuzzing
Debido a las dificultades que tiene implementar el fuzzing, la adopción por parte de los desarrolladores es baja. Exige tiempo, conocimiento y no promete resultados.
También hay que destacar que el impacto que tiene el software vulnerable puede llegar a ser muy alto por lo que algunos si optan por utilizar esta técnica.
Tradicionalmente se ha optado por la estrategia reactiva en cuanto a la seguridad. Se espera que los usuarios reporten bugs y problemas o que terceros encuentren fallos de seguridad y los publiquen. Algunos proveedores incluyen incentivos a reportar estos fallos mediante programas de recompensa.
Por estos motivos, habitualmente, solo ha existido un incentivo real en terceros para aplicar esta técnica. Existen muchas herramientas gratuitas para aplicar el fuzzing como AFL/AFL++, FuzzDB o Ffuf entre otras. Pero muy pocas de ellas se han usado por parte de los desarrolladores de software. Sin embargo, sí son comunes entre los investigadores de seguridad ya que realmente estas herramientas tienen la capacidad de buscar bugs de manera automatizada.
Existen algunos proyectos que intentan cerrar esta brecha. OSS-Fuzz, por ejemplo, está enfocado en proveer y automatizar parte de este proceso para que los proyectos de código abierto reciban reportes de posibles fallos de seguridad. El proyecto de OSS Fuzz ha descubierto más de 36000 bugs hasta enero de 2022.
Algunos proyectos de fuzzing open source
Para aquellos que tengan curiosidad sobre estas técnicas de fuzzing, enumeramos algunos proyectos open source para aplicarla que se encuentran en los mas usados y mantenidos en estos momentos.
- AFL (American Fuzzy Lop) / AFL++. Probablemente sean los más conocidos. AFL lleva sin actualizarse desde 2017 y por ello surge AFL++, un fork más actualizado y reciente. Es un proyecto muy extenso y con cierta complejidad. Permite aplicar diversas técnicas dentro del fuzzing y tiene soporte para binarios de diversas arquitecturas a través de QEMU o Unicorn emulator.
- LibFuzzer. Este proyecto está pensado para aquellos casos en los que tenemos acceso al código fuente. Para utilizarlo tenemos que implementar una función objetivo que se compilará junto con el código a testear mediante Clang. LibFuzzer usa partes del backend de LLVM para hacer seguimiento de la ejecución e intenta cubrir la mayor parte de las líneas de ejecución del binario. Es de los más enfocados a integrarse durante el proceso de desarrollo de la aplicación o librería.
- Honggfuzz. Otro proyecto con cierta complejidad y muchas opciones que configurar. Este proyecto está mantenido por Google y es parte de la iniciativa de OSS Fuzz. Destaca su posibilidad de ejecutarse en muy diversos sistemas operativos como Linux, *BSD, Android, Windows, Darwing/OS X…
Existen cientos de proyectos como Fuzzilli, boofuzz, jazzer, etc. Ante tanta variedad surge la duda de cual escoger y cual es el mejor. No existe una respuesta para esto, ya que como comentamos anteriormente, cada caso de ejemplo tiene unos requerimientos especiales. También hay que destacar que cada proyecto implementa sus estrategias de búsqueda automática de bugs, por lo que combinar distintos proyectos puede dar lugar a resultados que el uso individual no podría alcanzar.
Conclusiones
El fuzzing es una técnica compleja y que requiere una dedicación de tiempo, esfuerzo y recursos muy elevados.
A pesar de ello, la importancia de lograr aplicaciones y software seguros hace que existan iniciativas para su uso y recursos que permiten el descubrimiento de brechas de seguridad y otros bugs de manera automatizada, que un auditor haciendo una revisión de código probablemente no encontraría.