
Procesamos 800 millones de transacciones en la Blockchain de Ethereum. Te explicamos cómo
Tabla de contenidos
 Algo muy grande se está moviendo en la Blockchain de Ethereum. Fraude, especulación, productos financieros, evasión de impuestos, robos millonarios, arte, juegos, un nuevo sistema monetario… tú eliges la temática que te interesa
Algo muy grande se está moviendo en la Blockchain de Ethereum. Fraude, especulación, productos financieros, evasión de impuestos, robos millonarios, arte, juegos, un nuevo sistema monetario… tú eliges la temática que te interesa
Sea lo que sea que pretendas analizar en la Blockchain de Ethereum es necesario obtener primero las transacciones (dentro de los bloques) en alguna forma usable que permita su análisis.
¿Qué es la Blockchain de ethereum? (Grosso modo)
La blockchain de Ethereum es un histórico de transacciones. Descentralizado y compuesto de bloques, pero histórico al fin y al cabo.
¿Es igual que Bitcoin?
No. La diferencia notable con respecto a la primera blockchain de Bitcoin, es que además de transferir una cantidad de criptomoneda en cada transacción, también es posible interactuar con un contrato (smart contract).
Smart Contract
Un smart contract, de manera estricta, es un código ejecutable en la EVM (Ethereum Virtual Machine) que se puede invocar a través de transacciones. Una vez creados en la blockchain son inmutables, por lo que ni siquiera su autor puede modificarlos.
- Desde el punto de vista técnico, un smart contract es un programa, formado por funciones, instrucciones y variables.
- Desde un punto de vista general: los smart contracts han abierto un mundo de posibilidades, al poder crearse contratos de todo tipo, mayormente ligados al mundo financiero. Algunos ejemplos son nuevas monedas (tokens), sistemas de crédito, bolsas de valores descentralizadas, NFTs que establecen la propiedad de piezas de arte, juegos, etc.
Blockchain distribuida… ¿O replicada?
La blockchain se suele definir como una base de datos distribuida. Si bien tal vez sería más acertado usar el término “replicada” en su lugar.
Existe una red de nodos que son los encargados de mantener esta base de datos y de ir añadiendo bloques. Una característica de todos estos nodos es que tienen una copia exacta y completa de toda la blockchain. Dejaremos de lado los sistemas que se emplean para añadir de forma confiable nuevos bloques a la base de datos. Para el propósito de este artículo nos centraremos en cómo obtener esa base de datos.
Cómo descargar la Blockchain de Ethereum
Puesto que los nodos de la red Ethereum necesitan disponer de toda la blockchain (histórico de transacciones) para operar en ella, el primer paso que deben realizar es descargársela. Este proceso se llama “sincronización”.
Por tanto, la forma de descargar la blockchain es montar un nodo Ethereum que se conecte a la red y pase a formar parte de ella. Una vez en la red comenzará a descargarse todo el histórico de otros nodos.
Qué cliente Ethereum elegir
El primer paso es elegir un cliente Ethereum para que actúe como nodo.
Hay varias opciones disponibles, pero en este caso usaremos Geth (Go Ethereum), por ser la solución más popular y con un soporte muy amplio.
*Nota: Es interesante mencionar otra solución con un gran potencial y una altísima eficiencia: Nethermind. Si tenéis problemas con la velocidad de sincronización de Geth, es posible que os compense migrar a Nethermind.
Modos de sincronización de la blockchain
Antes de lanzar Geth y comenzar a sincronizar la blockchain, debemos decidir qué modo de sincronización deseamos.
Debido a la naturaleza de Ethereum existen dos modos de sincronización fundamentales:
- Fast: En este modo, se descargan únicamente la información de cada transacción y lo justo y necesario para comprobar la integridad de todos los bloques.
El objetivo de este modo es sincronizarse cuanto antes con el mínimo de información descargada y una reducida potencia de cómputo.
Con este modo podremos acceder al detalle de cada transacción (origen, destino, método de smart contract invocado, parámetros, etc.) pero no podremos acceder al resultado de la transacción. Es decir, desconocemos si fue exitosa o no, y en caso de serlo, los logs generados, además del gas total usado. - Full: Se descargan tanto los bloques como los recibos de transacción (receipts), que contienen el resultado de dichas transacciones: el gas usado, el estado (fallida o exitosa) y los logs generados.
Dependiendo del análisis que pretendamos realizar elegiremos una u otra opción. Sin embargo, la más recomendada es Full, puesto que seguramente necesitemos procesar también los resultados de las transacciones que estemos siguiendo.
El tercer modo de sincronización del que nadie habla
Existe un tercer modo de sincronización que no está listado como opción y que, para activarlo, es necesario añadir un parámetro adicional al ejecutar Geth. Este modo es el siguiente:
- Full archive: Se trata de una sincronización full + el estado guardado de la EVM en cada bloque.
Para conseguir este modo de sincronización es necesario añadir el parámetro: --gcmode archive
Por qué es útil?
Este modo es necesario para conocer el resultado que una transacción habría tenido en el pasado. Si quieres realizar una simulación sobre smart contracts que no controlas, necesitarás este modo.
Cuando un nodo está sincronizado, además de disponer del histórico completo de transacciones, tiene guardado el estado actual de la EVM. Este estado contiene el balance de cada wallet y el valor de todas las variables internas de los smart contracts. Esto es necesario para añadir nuevos bloques, puesto que las nuevas transacciones ejecutarán smart contracts y el resultado dependerá del contenido de sus variables internas.
Ejemplo: Un smart contract de un token ERC20 tendrá una variable con el balance (cantidad de ese token) de las wallets que interactuaron con él.
Algunas preguntas que puedes responder con este modo:
- Cuál era el balance de la wallet 0x78da1cc9a1f3bc5 el 1 de Enero de 2020 a las 2:00 pm?
- Cuál era el Total Supply de USDT el 1 de Julio?
- Cuál era el precio de DODGE en UniSwap el 1 de Julio?
- La compra del 10 tokens XX por 0.1 ETH habría sido exitosa a las 12:00 pm?
Lanzando Geth
Una vez decidimos el modo de sincronización, ya podemos lanzar Geth para que comience a sincronizar. Vamos a asumir que el modo será full. Ejecutamos lo siguiente:
geth.exe --datadir C:\full --syncmode full
De esta forma se arrancará Geth con lo básico. Sin embargo, es recomendable habilitar las dos siguientes opciones:
- RPC. A través de RPC podremos realizar consultas acerca del estado de la sincronización o sobre la blockchain. Es indispensable activar esta opción si vamos a integrar Geth con algún otro servicio/aplicación.
- Métricas. No es estrictamente necesario, pero siempre es útil tener acceso a gráficas sobre el rendimiento de Geth. Necesitaremos haber instalado una instancia de influxdb.
Si instalas Grafana, además, podrás tener un panel de control como el siguiente:
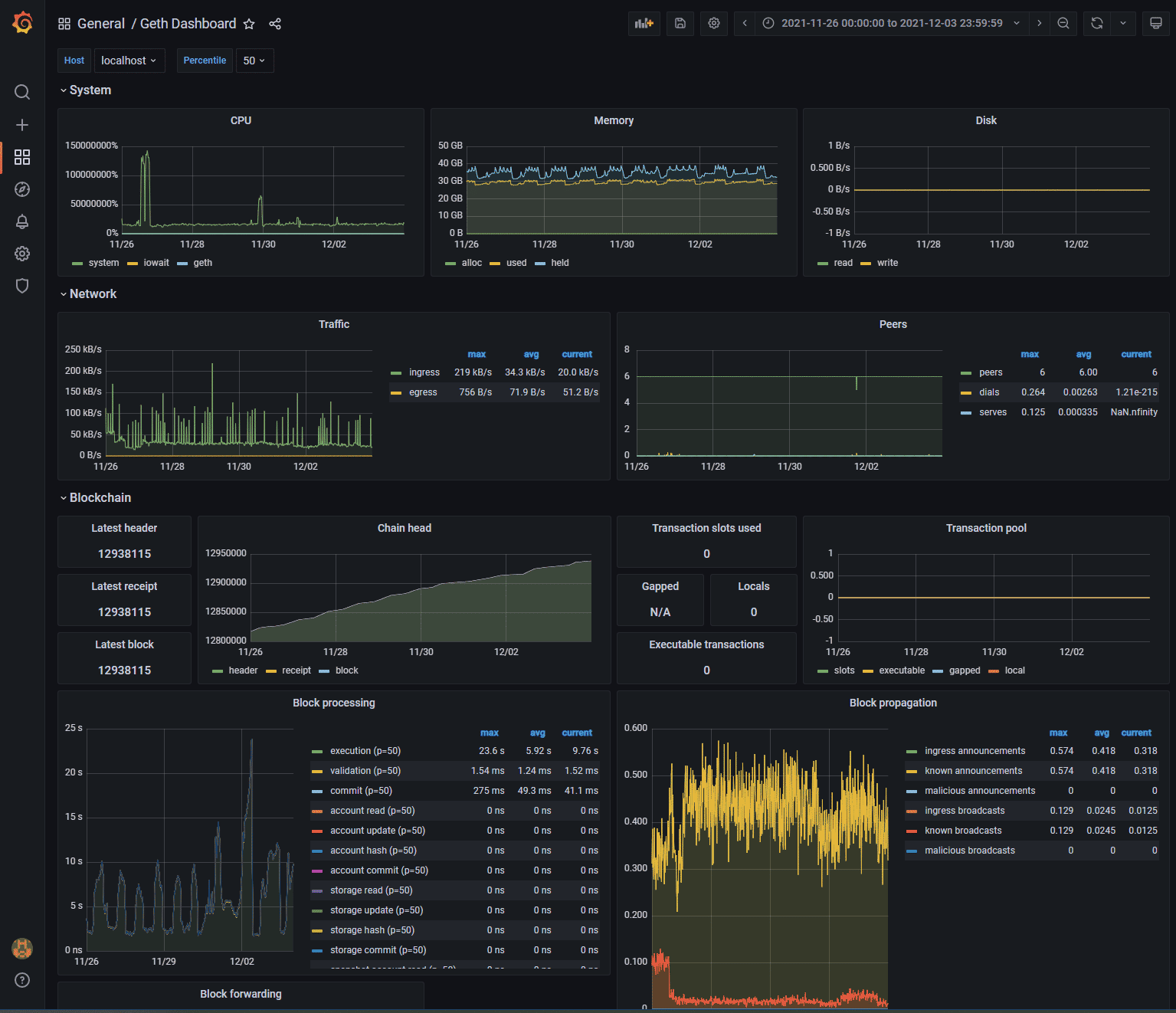
Para incluir estas dos opciones, ejecutar Geth de la siguiente forma:
geth.exe --datadir C:\full --syncmode full --http --http.api debug,eth,txpool,net,web3 --http.addr your_server_IP --metrics --metrics.influxdb --metrics.influxdb.endpoint "https://127.0.0.1:8086" --metrics.influxdb.username "influxuser" --metrics.influxdb.password "influxpassword"
Geth comenzará a imprimir logs con el estado de la sincronización. Tras un tiempo podrás ver algo como lo que sigue:
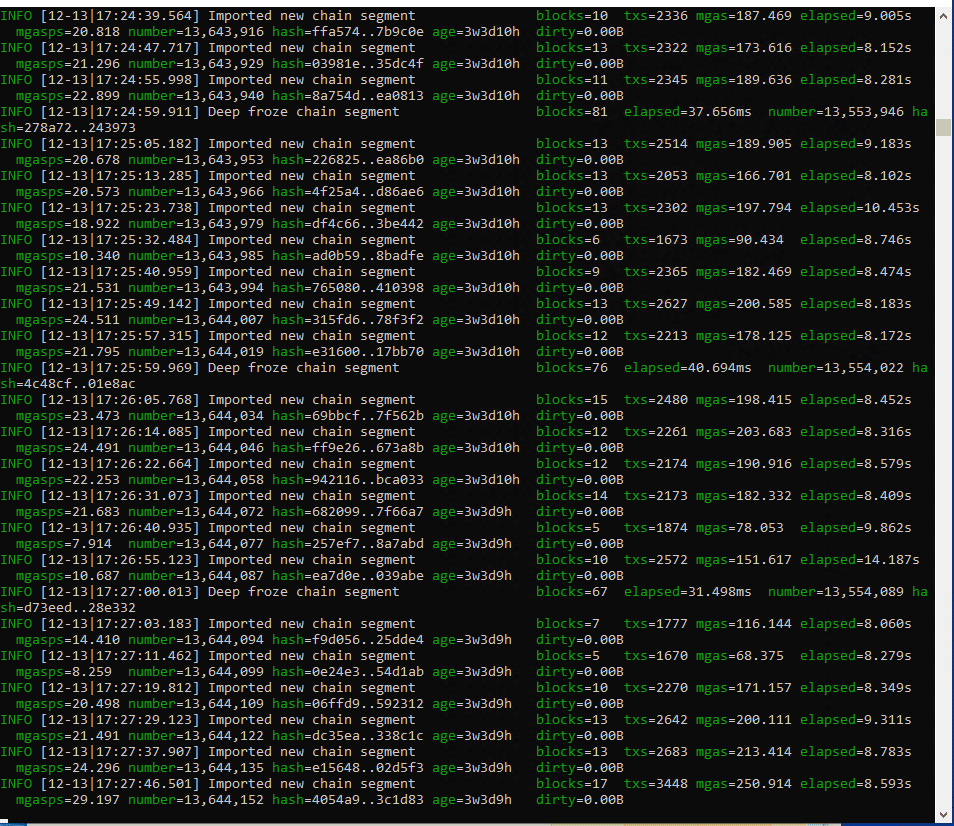
En donde se muestra en qué instante temporal se encuentra la sincronización. Podemos observar que esta instancia marca que faltan 3 semanas y 3 días por sincronizar.
*Nota: No extrapoles el tiempo que tardará la sincronización completa, porque al principio irá muy rápido y conforme avance se hará más lento. Esto es debido a que hace años había muchas menos transacciones por bloque que hoy, por lo que requiere más descarga y tiempo de cómputo.
Tiempo de espera
Hay que armarse de paciencia. Una sincronización full puede tardar 3 semanas, pero dependerá del hardware que tengas.
Una sincronización full + archive puede tardar más de 6 meses. Así, como lo oyes…
Accediendo a los datos
Una vez Geth se ha sincronizado, es hora de interactuar con la información almacenada para procesar transacciones.
Internamente Geth usa una base de datos LevelDB que guarda información en forma de pares clave-valor. Esta forma de interactuar con la información de la blockchain es muy engorrosa y dependiente del cliente Ethereum que estemos usando (Geth, en este caso).
Web3
Para resolver esto, disponemos de la API Web3. Es una API que los clientes Ethereum implementan para interactuar con la información guardada en su base de datos interna.
Esta API expone métodos para consultar la información de los bloques, transacciones, mempool, almacenamiento interno, firma, envío de transacciones, etc. La opción que habilitamos anteriormente al lanzar Geth (--http) permite la interacción con esta API a través del puerto 8545 por defecto.
Podemos interactuar manualmente con Web3 usando el propio Geth mediante el siguiente comando:
geth attach https://127.0.0.1:8545
Este comando se conectará a la instancia Geth ejecutada en localhost y habilitará un command prompt para ejecutar los métodos de la Web3.
Si ejecutamos una llamada eth.getBlockByNumber(11111111) obtendremos algo como lo siguiente:
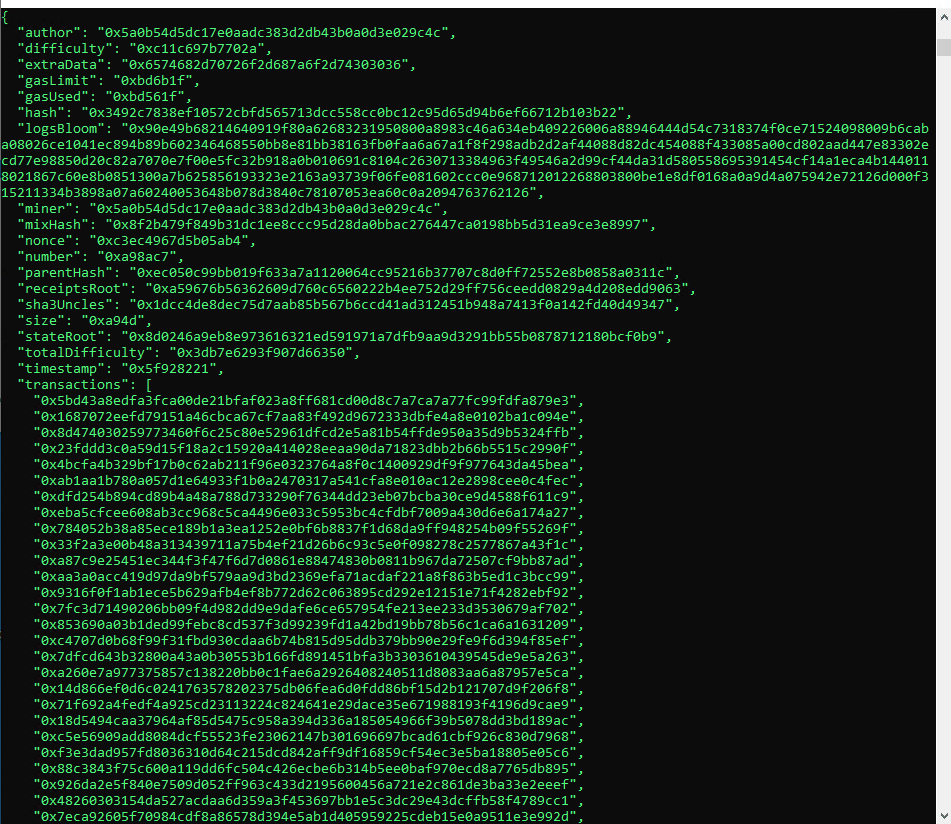
Volcado a base de datos local
Los métodos de consulta de Web3 son muy limitados y se centran en bloques y transacciones. Esto es, por lo general, insuficiente para realizar estudios que requieran del análisis de miles o incluso millones de transacciones, puesto que se eternizaría.
Como solución, optamos por volcar las transacciones necesarias para nuestro estudio a una base de datos que permita realizar consultas complejas y la creación de índices para reducir los tiempos de procesamiento. Esta base de datos puede ser relacional o no relacional, dependerá de los análisis que necesitemos realizar, la naturaleza de las consultas y el hardware disponible.
En nuestro caso optamos por una base de datos relacional MySQL.
*Nota: A la hora de realizar el volcado es importante deshabilitar todos los índices de la tabla. De lo contrario cada insert reconstruirá el índice y disparará el tiempo necesario para el volcado, hasta el punto de hacerlo inasumible.
Puesto que esta BD será únicamente de consulta y no va a recibir inserciones o borrados de distintos clientes de manera concurrente, optamos por un motor no transaccional MyISAM en lugar de InnoDB. El motivo es que no se necesitarán transacciones y los bloqueos a nivel de fila de InnoDB ralentizarán enormemente los update o delete que necesitemos realizar. Sin embargo, ésta es una decisión que variará según las necesidades de cada proyecto.
Aplicación de volcado
Para realizar este volcado crearemos una aplicación en C# que será la encargada de definir el modelo de BD, crear las tablas, realizar las consultas adecuadas en Web3 y volcar esos resultados en nuestro nuevo modelo.
ORM: EF Core
Es recomendable ahorrar tiempo de desarrollo y reducir la complejidad del proyecto usando un ORM. En nuestro caso hemos elegido un planteamiento con Entity Framework Core, Code First.
Sin embargo es importante resaltar que para el tratamiento masivo de datos es igualmente importante conocer bien la tecnología ORM que estemos usando para optimizarla y adaptarla a los requisitos de performance. La elección del ORM no debería introducir impactos significativos en el rendimiento.
Web3 library: Nethereum
La librería instalada para usar Web3 es Nethereum.
Para descargar de manera síncrona un rango de bloques podemos usar el siguiente código:
public List<BlockWithTransactions> GetBlocksByNumber(int start, int end = int.MaxValue) {
if (end == int.MaxValue)
end = (int)(ulong)G.Web3.Eth.Blocks.GetBlockNumber.SendRequestAsync().Await().Value;
List<BlockWithTransactions> blocks = new List<BlockWithTransactions>();
for(int blockN = start; blockN <= end; blockN++) {
blocks.Add(G.Web3.Eth.Blocks.GetBlockWithTransactionsByNumber.SendRequestAsync(new BlockParameter((ulong)blockN)).Await());
}
return blocks;
}
Dos notas acerca del código superior:
- la clase G es una clase estática que contiene una instancia de Nethereum.Web3.Web3.
- El método Await() es un método de extensión que fuerza la espera de la tarea hasta su finalización y retorna el resultado.
De esta forma tendremos la información de todas las transacciones realizadas entre dos bloques. Sin embargo sólo podemos acceder al “enunciado” de la transacción, pero no a su resultado.
Para descargar los resultados de la transacción (esto es: si fue fallida o no, y los logs generados) deberemos descargar el Receipt. En el siguiente snippet de código se muestra cómo:
var blocks = web3Blocks.GetBlocksByDate(1000000,1010000).ToList();
List<Task<TransactionReceipt>> tasksTransactionReceipts = new List<Task<TransactionReceipt>>();
var transactionsBlocks = blocks.SelectMany(bb => bb.Transactions).ToList();
foreach (var t in transactionsBlocks) {
tasksTransactionReceipts.Add(transactions.GetTransactionReceipt.SendRequestAsync(t.TransactionHash));
}
Task.WaitAll(tasksTransactionReceipts.ToArray());
En este caso realizamos la descarga de manera asíncrona para optimizar el rendimiento.
Big Data
Para realizar descargas masivas de datos en la Blockchain de Ethereum no podremos usar estos dos snippets de código de manera directa, puesto que no habrá memoria RAM suficiente para alojar millones de bloques con todas sus transacciones.
Por tanto, deberemos hacerlo en chunks de unos cuantos miles e irlo volcando en la BD. Es importante diseñarlo de forma que se ejecute lo más asíncronamente posible para reducir los tiempos de volcado y maximizar el uso de los recursos hardware.
En cualquier caso, en nuestra experiencia, el cuello de botella más importante se encuentra en Geth y los tiempos de búsqueda necesarios para obtener a través de su API la información de los bloques y transacciones.
El volcado de 12 meses de transacciones puede tardar más de 48 horas.
Listo!
En este punto, tras una «breve» espera, ya tendremos a nuestra disposición una BD con millones de transacciones listas para ser analizadas.
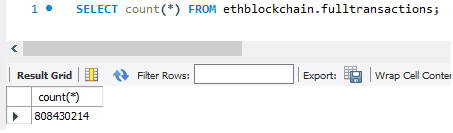
Próximos pasos
Casi con total seguridad, las transacciones en bruto no nos aportarán toda la información necesaria. Conoceremos las direcciones de origen y destino, la cantidad de ETH que se mueve y un campo binario con la información para el smart contract.
Es en este binario donde se encuentran los detalles de la petición (método que se ejecuta del smart contract y los parámetros), por lo que tendremos que procesar estos binarios si queremos más detalle. Afortunadamente, Nethereum cuenta con un módulo para hacer esta tarea. Esto nos permitirá realizar análisis de ciberseguridad e ingeniería inversa sobre los smart contracts.
Este parseo, por lo general, lo centraremos únicamente en los smart contracts concretos que estemos analizando.
Adicionalmente, es posible que necesitemos conocer cuál fue el resultado de la interacción con el smart contract, por lo que necesitaremos parsear en muchos casos los logs que haya emitido. Estos logs son totalmente dependientes del smart contract y no siguen ningún estándar en particular, por lo que se deberá realizar una implementación adhoc para aquellos que vayamos a analizar.
¿Algo más?
Por supuesto! Ya tenemos todo listo no? Una BD ingente con un modelo perfectamente diseñado y todos los datos que necesitamos. Y ahora?
Hora de aplicar estadística, modelos bayesianos, algoritmos genéticos, Deep Learning… o lo que uno más guste.
Descubre nuestro trabajo y nuestros servicios de ciberseguridad en www.tarlogic.com/es/
Este artículo forma parte de una serie de articulos sobre Blockchain de Ethereum
- Procesamos 800 millones de transacciones en la Blockchain de Ethereum. Te explicamos cómo
- Monitorizando cripto atacantes en la blockchain de Ethereum: Ataques sandwich
- Si haces trading en la blockchain de Ethereum, perderás tu dinero. Te explicamos por qué