
Identificación de funciones en el firmware de ESP32 mediante Ghidra FIDB

La ingeniería inversa del firmware en dispositivos ESP32 se ve ralentizada por la ausencia de símbolos de depuración, obligando a la identificación manual de funciones. En este artículo se explica cómo hacer uso de las Function Identification Databases (FIDB) de Ghidra junto con ESP-IDF para automatizar la identificación de funciones y transformar un binario opaco en código comprensible en cuestión de minutos.
Una parte importante en los proyectos de análisis de vulnerabilidades en dispositivos hardware e IoT es el análisis del firmware. El firmware por lo general está compilado sin símbolos de depuración, debido a las restricciones en el tamaño de memoria de almacenamiento que presentan. Esto hace que la tarea de ingeniería inversa se complique debido a que no hay ninguna información sobre las funciones del binario y deben ser identificadas manualmente.
El microcontrolador ESP32 ha ganado popularidad en dispositivos embebidos debido a su bajo coste y las comunicaciones WiFi y Bluetooth integradas. El análisis del firmware para este chip presenta las mismas dificultades derivadas de la falta de símbolos en los binarios de firmware.
Espressif, el fabricante del ESP32, proporciona un SDK para programar la familia de chips ESP32, el ESP-IDF. Este framework de desarrollo consta de todos los componentes necesarios para la creación de un proyecto de firmware que se ejecute en los chips ESP32, desde los drivers de los periféricos a más bajo nivel a librerías avanzadas.
El uso de un mismo SDK para la gran mayoría de proyectos basados en esta familia de microcontroladores hace que el firmware comparta una gran cantidad de código. Aquí es donde entra en juego la funcionalidad de Function Identification Databases (FIDB) de Ghidra que nos permite generar bases de datos con metadatos de las funciones del ESP-IDF e identificarlas en binarios sin símbolos de manera automatizada. Esto agiliza el proceso de ingeniería inversa del firmware, ya que gracias a FIDB no es necesaria la identificación de funciones del SDK manualmente.
Ghidra Function ID Databases (FIDB)
Las Function ID Databases (FIDB) son bases de datos indexadas que permiten a Ghidra identificar automáticamente funciones de librerías conocidas dentro de binarios compilados mediante comparación de hashes. Cuando un programa se compila estáticamente con librerías, las funciones pierden sus nombres originales y quedan como bloques anónimos de código máquina. FIDB resuelve este problema almacenando hashes precalculados de funciones conocidas junto con sus metadatos (nombre, versión de librería, variante de compilación), permitiendo recuperar la identificación original.
El proceso consta de dos partes:
- Generación de la base de datos FIDB: Se recorren todas las funciones de uno o más binarios, cuyas funciones se encuentran etiquetadas con nombres, es decir, en binarios con símbolos. Para cada función se generan dos hashes que se almacenan en la base de datos junto con su nombre y otros metadatos.
- Uso de la base de datos: En el proceso de identificación de funciones en un binario sin símbolos, se analiza cada función del binario, generando los dos hashes para cada una de ellas. Los hashes generados se comparan con los almacenados en la base de datos FIDB, generada anteriormente, y si se encuentra una coincidencia, se usan los metadatos de la función en la base de datos para etiquetar la función del binario analizado.
Para cada función se calculan dos hashes:
- full hash: incluye los mnemónicos (los nombres de las instrucciones en ensamblador, p. ej. MOV, ADD, JMP) y la información de direccionamiento, pero ignora valores constantes específicos, haciéndolo resistente a reubicaciones durante el linking.
- specific hash: añade todos los elementos incluidos en el full hash y además añade valores de operandos constantes, cuando estas constantes no son de direccionamiento.
Para resolver coincidencias o ambigüedades, el sistema examina el árbol de llamadas de la función. Si dos funciones son idénticas pero llaman a subfunciones diferentes, el hash de esas subfunciones permite distinguirlas.
El analizador calcula puntuaciones basadas en instrucciones coincidentes, sumando también las puntuaciones de funciones padre e hijo que coincidan. FIDB permite aplicar umbrales configurables a estas puntuaciones para filtrar coincidencias aleatorias en funciones pequeñas, reportando el nombre cuando puede reducir candidatos a uno solo, o múltiples opciones cuando la ambigüedad persiste.
Identificando la versión del ESP-IDF
Es posible que el firmware que vayamos a analizar este compilado con una versión del ESP-IDF antigua. En las actualizaciones se introducen cambios en el código y en la API, por esto, para generar una bases de datos de identificación de funciones de Ghidra (FIDB) que identifique el máximo de funciones del firmware del dispositivo, debe realizarse con la versión correcta del ESP-IDF.
Para identificar la versión del IDF usada en el firmware que se está analizando existen diferentes métodos.
Primero podemos echar un vistazo a los logs del dispositivo por el puerto serie. Los chips de ESP32 implementan una interfaz UART a través de la cual el bootloader expone una interfaz que permite entre otras cosas leer y escribir el firmware de la memoria flash. Por defecto, en esta interfaz el firmware escribe información de depuración, que incluyen mensajes tanto del ESP-IDF como de la propia aplicación. Mientras, inicia el ESP-IDF se escribe en la interfaz UART el número de versión.terface.
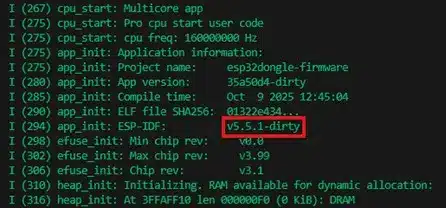
Sin embargo, es muy común que los logs de depuración estén deshabilitados en dispositivos de depuración. En este caso, la sección de código de usuario en el binario del firmware incluye una cabecera que contiene el número de versión del ESP-IDF.
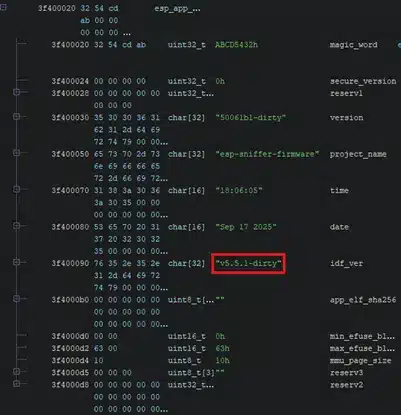
Una vez obtenido el número de versión, se instala esa versión y compila el código de ESP-IDF de dicha versión. Cada versión tiene su propio toolchain de compilación, esto es una ventaja para la identificación de funciones mediante FIDB, ya que por defecto el propio IDF fija un compilador concreto para todas las compilaciones, lo que garantiza que el código máquina generado para un fragmento de código será el mismo para todos los dispositivos con esa versión de ESP-IDF.
Durante la instalación de ESP-IDF es importante fijar la versión del IDF en el tag del repositorio de GitHub durante la instalación del SDK.
mkdir -p ~/esp cd ~/esp git clone -b v5.5.1 --recursive https://github.com/espressif/esp-idf.git cd ~/esp/esp-idf ./install.sh
Una vez instalado el ESP-IDF de la misma versión que el dispositivo que se está analizando, se compila el código del ESP-IDF usando los distintos proyectos de ejemplo que se distribuyen con el SDK IDF, estos se encuentran dentro del directorio examples.
Un buen enfoque para generar una base de datos FIDB con el máximo número de funciones de ESP-IDF es compilar todos los proyectos de ejemplo para generar una base de datos con la mayoría de las componentes del ESP-IDF y poder reutilizarla en proyectos posteriores. En caso de querer compilar algún componente que no se use en ningún proyecto de ejemplo del ESP-IDF, es necesario crear un proyecto que incluyera las llamadas a esos componentes para que se incluyan en el binario.
Para compilar un proyecto de ejemplo, se copia el directorio del proyecto del IDF al directorio de compilación y se ejecuta la herramienta que proporciona IDF:
idf build
Creando el proyecto de Ghidra
Una vez compilado el proyecto, se genera un ejecutable en formato ELF en el directorio build. Este archivo ELF contiene los símbolos que una vez extraídos, permiten a Ghidra identificar todas las funciones del código y generar una base de datos FIDB con ellas.

Los proyectos pueden estar compilados con diferentes optimizaciones y la configuración del IDF permite compilar con optimización de tamaño (-Os) o de rendimiento (-O2). Es recomendable generar los binarios de cada proyecto con ambas optimizaciones, ya que cada una puede generar código máquina distinto y no sabemos con qué optimización se ha compilado el firmware que se está analizando, maximizando de esta manera las posibilidades de encontrar las funciones posteriormente.
Para seleccionar la optimización del compilador se usa el menú de configuración de ESP-IDF:
idf menuconfig
Compiler Options > Optimization Level
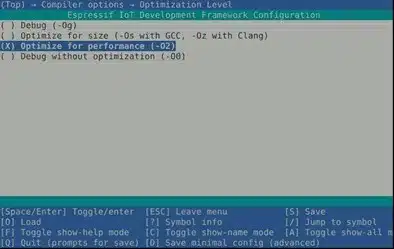
Una vez seleccionada la optimización del compilador, volvemos a compilar los proyectos con esa optimización.
Una vez compilados todos los proyectos que incluyen las funciones que nos interesa identificar, creamos un proyecto de Ghidra e importamos los binarios en formato ELF.
Ahora tenemos un proyecto de Ghidra con todos los binarios de los proyectos de ejemplo con varias optimizaciones. Es necesario ejecutar un autoanálisis para cada binario desde la herramienta Code Browser. Este análisis etiqueta y decompila todas las funciones del binario. Una vez analizado cada programa, lo guardamos.
Generando la base de datos FIDB
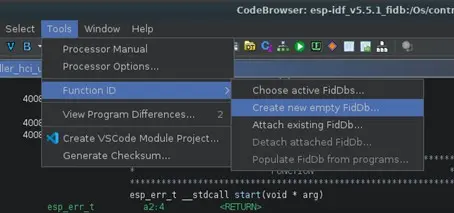
Una vez tenemos analizados todos los binarios procedemos a crear las bases de datos FIDB de todos ellos abriendo con la herramienta Code Browser cualquiera de los binarios del proyecto de Ghidra y desde ahí se crea la base de datos FIDB en la pestaña Tools > Function ID > Create new empty FIDB… seleccionando la ruta donde queremos guardar la base de datos.
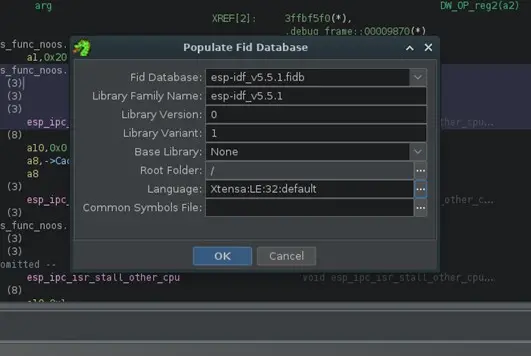
Mediante la opción Populate FiDb from programs… del mismo menú se crea la base de datos FIDB a partir de los programas del proyecto. Nos pide una serie de datos como nombre, la versión, directorio raíz del proyecto para incluir todos los programas del proyecto y el «language» donde seleccionamos Xtensa:LE:32:default que es la la arquitectura del ESP32.
Cuando finaliza la creación de la base de datos FIDB, Ghidra muestra un reporte de las funciones añadidas a la base de datos, en este ejemplo se han añadido un total de 23361 funciones. También indica que 12810 funciones han sido excluidas, la gran mayoría porque están duplicadas en los diferentes binarios del proyecto.
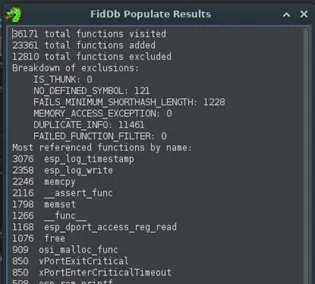
En este momento ya tenemos un archivo con extensión .fidb que es la base de datos FIDB generada y que puede ser importado en diferentes instancias de Ghidra para la identificación de las funciones.
Es posible explorar el contenido de la base de datos FIDB activando el plugin de depuración de FIDB desde la ventana de Code Browser en las opcion de configuración en File > Configure, dentro de la sección «Developer» abrimos el menú de configure y activamos la opción FidDebugPlugin.
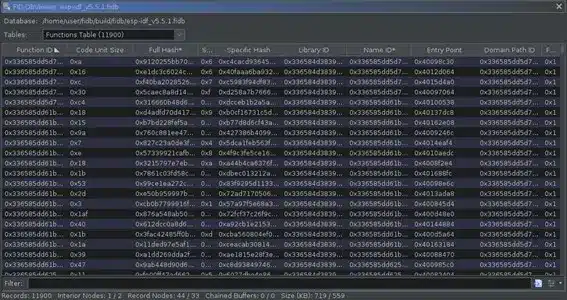
Ahora en la sección Tools > Function ID aparecen más opciones como Table Viewer que nos permite navegar a través de la base de datos FIDB y explorar su contenido.
Identificando funciones en el firmware sin símbolos
Ahora que tenemos la base de datos FIDB podemos usarla para identificar funciones en un archivo binario del firmware sin símbolos.
Desde Ghidra con el proyecto del firmware abierto nos aseguramos de tener la base de datos FIDB importada desde la opcion Tools > Function ID > Attach existing FidDb…
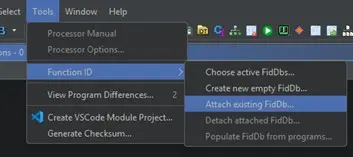
Ahora se realiza una pasada de análisis con el analizador Function ID. Este analizador genera los hashes de las funciones del binario y los compara con los almacenados en la base de datos FIDB de modo que las funciones cuyo hash coincida se etiquetan automáticamente.
El analizador se ejecuta desde la ventana de análisis en Analysis > Auto Analyze ‘file.bin’… En la ventana de análisis seleccionamos el analizador «Function ID». Al analizador se le pueden pasar distintas opciones:
- Always Apply FID labels: Si el analizador detecta una coincidencia con una función, le asignará el nombre de la FIDB incluso si ya está identificada con un nombre.
- Create Analysis Bookmarks: El analizador crea bookmarks en las funciones identificadas.
- Instruction Count Threshold: El umbral de las instrucciones mínimas que tienen que coincidir con las funciones de la base de datos FIDB para que el analizador identifique la función. Un umbral muy bajo puede provocar falsos positivos; uno muy alto provoca que únicamente grandes funciones sean identificadas.
- Multiple Match Threshold: umbral mínimo para que se reporten coincidencias múltiples cuando no se puede determinar un único nombre de función. Si el umbral es alto, se reportan menos coincidencias múltiples; si es bajo, se reportan coincidencias múltiples poco fiables.
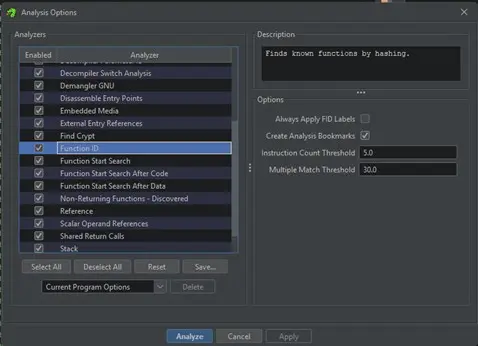
El análisis con la base de datos FIDB se identifican gran parte de las funciones de ESP-IDF.
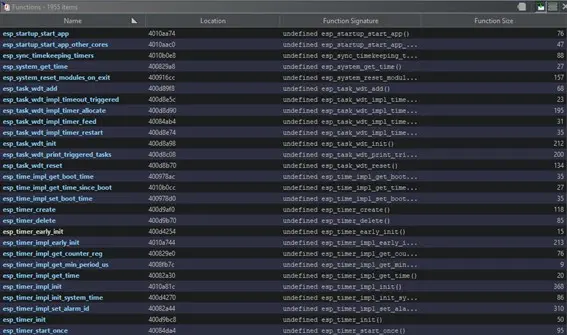
Esto facilita el análisis de la parte de aplicación del firmware del dispositivo ya que las funciones del propio framework se han identificado gracias a FIDB.
En conclusión
La funcionalidad de bases de datos de identificación de funciones (FIDB) de Ghidra es una potente herramienta a la hora de realizar ingeniería inversa, concretamente en código sin símbolos de depuración como el firmware de dispositivos.
En este artículo se ha aprovechado que la gran mayoría de dispositivos basados en ESP32 comparten el mismo código base del SDK proporcionado por Espressif. Esto permite generar una base de datos una sola vez y reutilizarla en los distintos proyectos de ingeniería inversa para este tipo de chips.
Aunque la creación de estas bases de datos puede ser un proceso laborioso, requiriendo compilar múltiples proyectos para abarcar el ESP-IDF completo, es fácilmente automatizable, gracias a la utilidad de análisis headless de Ghidra. Existen articulos donde se explora el proceso de importación, análisis y creación de bases de datos FIDB de forma automatizada.
https://blog.threatrack.de/2019/09/20/ghidra-fid-generator
En definitiva, el uso de FIDB en Ghidra aplicado a la familia de chips ESP32 supone un cambio significativo en la forma de abordar el análisis de firmware sin símbolos, permitiendo pasar de un enfoque manual y repetitivo a uno sistemático y reutilizable. Al invertir tiempo una sola vez en la generación de una base de datos bien construida y alineada con la versión concreta del ESP-IDF, se consigue acelerar enormemente futuros procesos de ingeniería inversa, reducir errores y centrar el esfuerzo en el análisis de la lógica específica del dispositivo y sus posibles vulnerabilidades, en lugar de en la identificación del código común del framework.
Referencias:
- https://htmlpreview.github.io/?
- https://github.com/NationalSecurityAgency/ghidra/blob/master/Ghidra/Features/FunctionID/src/main/help/help/topics/FunctionID/FunctionID.html
- https://blog.threatrack.de/2019/09/20/ghidra-fid-generator/
- https://github.com/threatrack/ghidra-fid-generator
- https://docs.espressif.com/projects/esp-idf/en/stable/esp32/get-started/linux-macos-setup.html