
Cracking de claves WiFi con Pyrit en Amazon ec2
Amazon AWS dispone entre su catálogo de Elastic Compute Cloud (EC2) de dos instancias optimizadas para el uso de computación paralela basada en GPU.
La instancia cg1.4xlarge perteneciente a la generación anterior de instancias dispone de 22 GiB de RAM, 33,5 unidades EC2, 2 GPU NVIDIA Tesla «Fermi» M2050, 690 GB de almacenamiento local y una conexión Ethernet de 10 gigabits. Con la nueva generación, Amazon ha introducido la instancia g2.2xlarge que proporciona 15 GiB de RAM, 26 unidades EC2, 1 GPU NVIDIA GRID (Kepler GK104), 60 GB de almacenamiento local y una conexión Ethernet de 10 gigabits.
Este tipo de instancias son adecuadas para realizar tareas de cracking puntuales, ya que Amazon cobra por horas de uso de las instancias. Por ello, en caso de no poder adquirir hardware específico para esta tarea, utilizar la infraestructura de Amazon EC2 puede ser una buena idea para crackear claves WiFi.
En el presente artículo se explicará como preparar una instancia cg1.4xlarge o g2.2xlarge para utilizar herramientas de cracking que hagan uso de computación basada en GPU, como puede ser Pyrit.
El primer paso será será iniciar la instancia con la AMI (Amazon Machine Image) Amazon Linux AMI (HVM), que actualmente posee el identificador ami-7c56b80b. Esta AMI ha sido creada por Amazon para el uso de este tipo de instancias, que requieren interactuar con el hardware de los servidores.
Cuando la instancia haya finalizado la fase de inicialización se podrá establecer una conexión SSH, con el usuario ec2-user, para poder llevar a cabo la instalación de las utilidades necesarias. Para ello se deben seguir los siguientes pasos.
- Instalación de las dependencias de CUDA, Pyrit y Scapy
# yum -y install subversion python-devel openssl-devel zlib-devel libpcap-devel glibc-devel gcc kernel-devel gcc-c++
- Descarga e instalación de CUDA
# wget https://developer.download.nvidia.com/compute/cuda/5_5/rel/installers/cuda_5.5.22_linux_64.run
# chmod +x cuda_5.5.22_linux_64.run
# ./cuda_5.5.22_linux_64.run
- Actualización de las variables de entorno PATH y LD_LIBRARY_PATH, tal y como muestra el instalador de CUDA
# export PATH=/usr/local/cuda-5.5/bin:$PATH
# export LD_LIBRARY_PATH=/usr/local/cuda-5.5/lib:/usr/local/cuda-5.5/lib64:$LD_LIBRARY_PATH
- Descarga e instalación de Scapy, utilizado por Pyrit para el manejo de paquetes
# wget https://www.secdev.org/projects/scapy/files/scapy-latest.zip
# unzip scapy-latest.zip -d scapy
# cd scapy/*/
# python setup.py install
- Descarga e instalación de Pyrit
# svn checkout https://pyrit.googlecode.com/svn/trunk/ pyrit
# cd pyrit/pyrit
# python setup.py install
# cd ../cpyrit_cuda
# sed -i -e "s/NVIDIA_INC_DIRS = \[\]/NVIDIA_INC_DIRS = \[\'\/opt\/nvidia\/cuda\/include\'\]/" setup.py
# python setup.py install
Una vez finalizada la instalación de Pyrit será posible visualizar los procesadores con los que puede interactuar. Para ello se debe ejecutar el siguiente comando:
# pyrit list_cores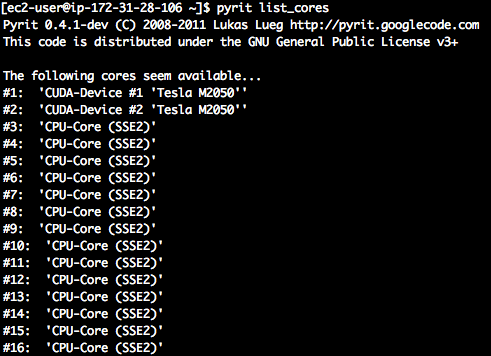 Imagen 1: Cores de una instancia cg1.4xlarge
Imagen 1: Cores de una instancia cg1.4xlarge 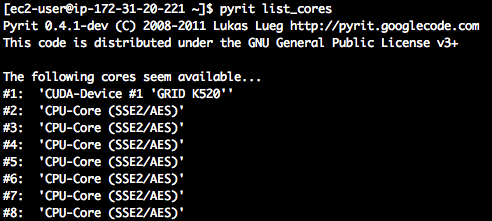
Imagen 2: Cores de una instancia g2.2xlarge
Para comprobar el rendimiento que puede obtener Pyrit en cada tipo de instancia, se puede utilizar el siguiente comando:
# pyrit benchmark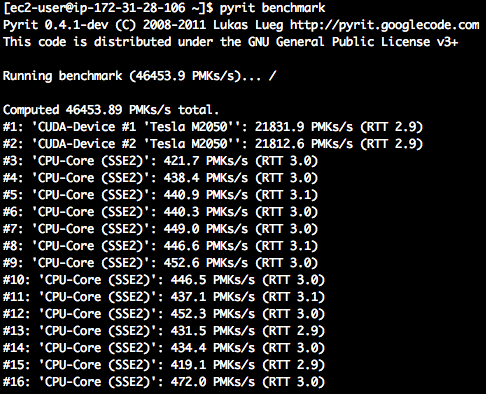
Imagen 3: Benchmark de una instancia cg1.4xlarge
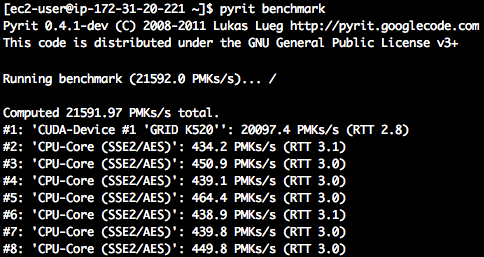
Imagen 4: Benchmark de una instancia g2.2xlarge
Como se puede apreciar el número de PMK por segundo que es capaz de procesar Pyrit en una instancia de la generación anterior es más del doble que en la de la generación actual. Aunque el rendimiento es menor, en términos de rendimiento económico es más rentable la instancia de nueva generación (g2.2xlarge), ya que el coste por hora de una esta es $0.702 frente a $2.36 de una instancia de la anterior generación.
En el siguiente artículo se explicará como crear una granja de instancias con Pyrit que permitan aumentar el rendimiento sin elevar drásticamente el coste económico.
Descubre nuestro trabajo y nuestros servicios de ciberseguridad en www.tarlogic.com/es/
En TarlogicTeo y en TarlogicMadrid.